Hierarchical Policy Gradient Algorithms
Hierarchical Policy Gradient Algorithms
Math
Notation
M : the overall task MDP.
{M0, M1, M2 , M3 , . . . , Mn } : a finite set of subtask MDPs.
Mi : subtask, models a subtask in the hierarchy.
M0 : root task and solving it solves the entire MDP M.
i : non-primitive subtask, paper uses subtask to refer to non-primitive subtask.
Si : state space for non-primitive subtask i.
Ii : initiation set.
Ti : set of terminal state.
Ai : action space.
Pi : transition probability function.
Ri : reward function.
a : primitive action, is a primitive subtask in this decomposition, it terminates immediately after execution.
μi : subtask i policy.
μ={μ0 , μ1 , μ2 , μ3 , . . . , μn} : hierarchical policy
μi(θi) : randomized stationary policies parameterized in terms of a vector θi ∈ ℜK .
μi(s, a, θi) : probability of taking action a in state s under the policy corresponding to θi.
s*i : absorbing state, all terminal states (s ∈ Ti ) transit with probability 1 and reward 0 to an absorbing state s*i .
: The probability that subtask i starts at state s.
: MDP for subtask i .
: MDP for subtask i transition probabilities.
: the set of all transition matrices
.
: weighted reward-to-go, the performance measure of subtask i formulated by parameterized policy μi(θi).
: reward-to-go of state s.
: the first future time that state s*i is visited.
: gradient of the weighted reward-to-go
with respect to
.
: steady state probability distribution of being in state s.
: mean recurrence time.
: usual action-value function.
: estimate gradient of the weighted reward-to-go
with respect to
, i.e.,
.
tm : the time of the mth visit at the recurrent state s*i .
: an estimate of Qi .
: step size parameter.
Policy Gradient Formulation
After decomposing the overall problem into a set of subtasks, the paper formulates each subtask as policy gradient reinforcement learning problem. The paper focus on episodic problems, so it assume that the overall task (root of the hierarchy) is episodic.
Assumption 1
For every state s ∈ Si and every action a ∈ Ai , μi(s, a, θi) as a function of θi , is bounded and has bounded first and second derivatives. Furthermore, we have
where is bounded, differential and has bounded first derivatives.
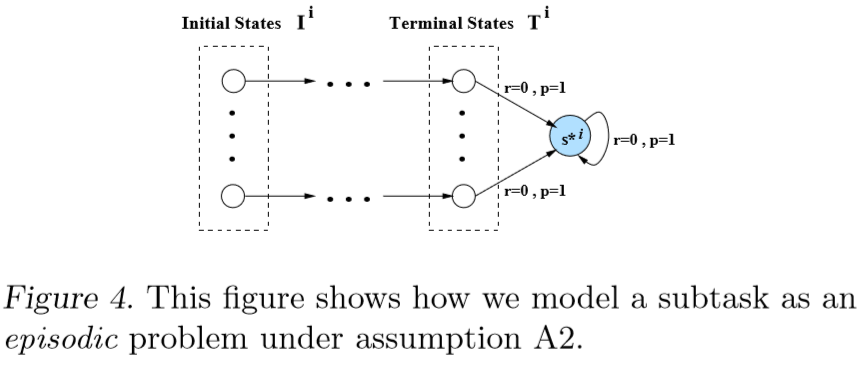
Assumption 2
Subtask Termination
There exists a state s*i ∈ Si such that, for every action a ∈ Ai , we have
and for all stationary polices μi(θi) and all states si ∈ Si, we have
Under this model, we define a new MDP for subtask i transition probabilities:
where
: the probability that subtask i starts at state s.
Let be the set of all transition matrices
. We have the following result for subtask i.
Lemma 1
Let assumptions A1 and A2 hold. Then for every , and every state
, we have
where
Lemma 1 is equivalent to assume that the MDP is recurrent, i.e., the underlying Markov chain for every policy μi(θi) in this MDP has a single recurrent class and the state s*i is recurrent state.
Performance Measure Definition
Paper defines weighted reward-to-go , the performance measure of subtask i formulated by parameterized policy μi(θi).
Assumption A2 holds
where is reward-to-go of state s.
where is the first future time that state s*i is visited.
Optimizing the Weighted Reward-to-Go
Proposition 1
If assumptions A1 and A2 hold
Cycle between consecutive visits to recurrent state s*i = renewal cycle
can be estimated over a renewal cycle as
(P1)
where tm is the time of the mth visit at the recurrent state s*i .
From P1, the paper obtains the following procedure to update the parameter vector along the approximate gradient direction at every time step.
(P2)
P2 provides an unbiased estimate of . For systems involving a large state space, the interval between visits to state s*i can be large. As a consequence, the estimate of
might have a large variance.
: step size parameter and satisfies the following assumptions.
Assumption 4
‘s are deterministic, nonnegative and satisfy
Assumption 5
‘s are non-increasing and there exists a positive integer p and a positive scalar A such that
for all positive integers n and t.
The paper has the following convergence result for the iterative procedure in P2 to update the parameters.
Proposition 2
Let assumption A1, A2, A4 and A5 hold, and let be the sequence of parameter vectors generated by P2. Then,
converges and
with probability 1.
Download: pdf