Hierarchical Actor-Critic
Hierarchical Actor-Critic
Download Hierarchical_Actor-Critic Flowchart
Terminology
| Artificial intelligence | Optimization/decision/control | |
| a | Agent | Controller or decision maker |
| b | Action | Control |
| c | Environment | System |
| d | Reward of a stage | (Opposite of) Cost of a stage |
| e | Stage value | (Opposite of) Cost of a state |
| f | Value (or state-value) function | (Opposite of) Cost function |
| g | Maximizing the value function | Minimizing the cost function |
| h | Action (or state-action) value | Q-factor of a state-control pair |
| i | Planning | Solving a DP problem with a known mathematical model |
| j | Learning | Solving a DP problem in model-free fashion |
| k | Self-learning (or self-play in the context of games) | Solving a DP problem using policy iteration |
| l | Deep reinforcement learning | Approximate DP using value and/or policy approximation with deep neural networks |
| m | Prediction | Policy evaluation |
| n | Generalized policy iteration | Optimistic policy iteration |
| o | State abstraction | Aggregation |
| p | Episodic task or episode | Finite-step system trajectory |
| q | Continuing task | Infinite-step system trajectory |
| r | Afterstate | Post-decision state |
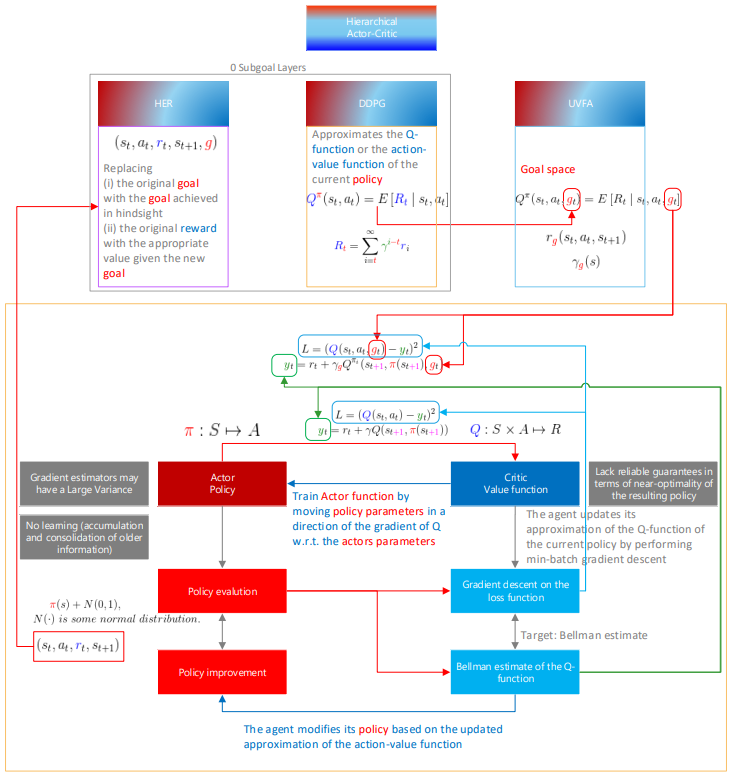
Hierarchical Actor-Critic (HAC) helps agents learn tasks more quickly by enabling them to break problems down into short sequences of actions. They can divide the work of learning behaviors among multiple policies and explore the environment at a higher level.
In this paper, authors introduce a novel approach to hierarchical reinforcement learning called Hierarchical Actor-Critic(HAC). The algorithm enables agents to learn to divide tasks involving continuous state and action spaces into simpler problems belonging to different time scales.

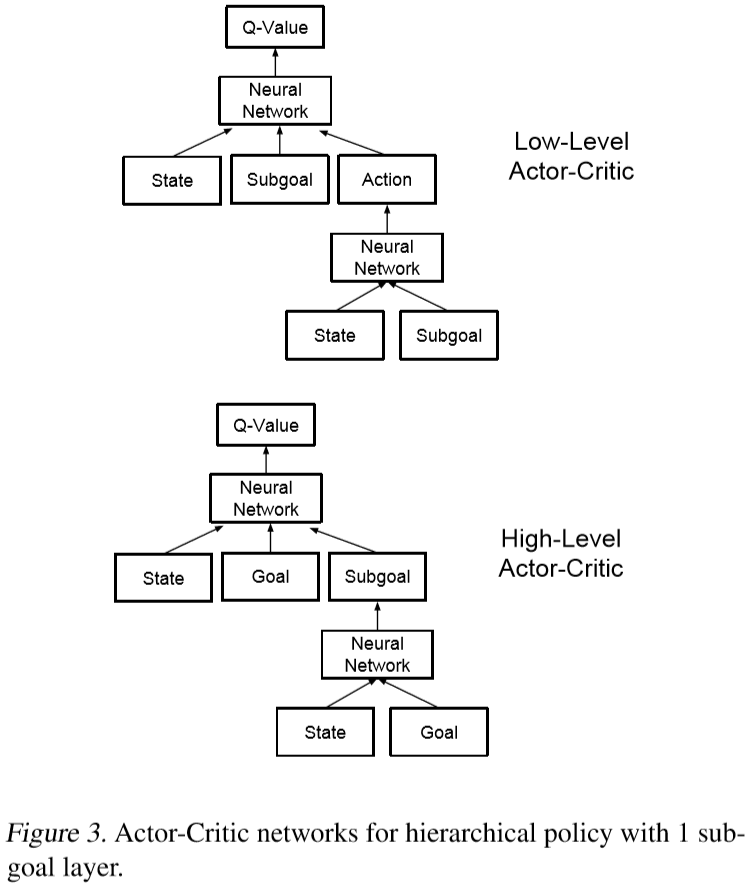
The low-level policy outputs actual agent actions so the vertical lines for the low-level policy can be interpreted as subgoals requiring one action.
In the figure, the high-level policy breaks down the end goal into three subgoals with relatively large time resolutions. The mid-level policy specializes in dividing each subgoal from the high-level policy into three subgoals belonging to shorter time scales. Finally, the low-level policy specializes in decomposing each subgoal from the mid-level policy into three agent actions which represent the smallest time resolution.
HAC builds off three techniques from the reinforcement learning literature:
(i) the Deep Deterministic Policy Gradient (DDPG) learning algorithm (Lillicrap et al., 2015)
(ii) Universal Value Function Approximators (UVFA) (Schaul et al., 2015)
(iii) Hindsight Experience Replay (HER) (Andrychowicz et al., 2017)
DDPG: an actor-critic algorithm
DDPG serves as the key learning infrastructure within Hierarchical Actor-Critic. DDPG is an actor–critic algorithm and thus uses two neural networks to enable agents to learn from experience. The actor network learns a deterministic policy that maps from states to actions
The critic network approximates the Q-function or the action-value function of the current policy
where
Rt : the discounted sum of future rewards
Thus, the critic network maps from (state, action) pairs to expected long-term reward:
Policy evaluation
The agent first interacts with the environment for a period of time using a noisy policy The transitions experienced are stored as
(st , at , rt , st+1 ) tuples in a replay buffer.
The agent then updates its approximation of the Q-function of the current policy by performing min-batch gradient descent on the loss function:
the target yt is the Bellman estimate of the Q-function
Policy improvement
The agent modifies its policy based on the updated approximation of the action-value function. The actor function is trained by moving its parameters in the direction of the gradient of Q w.r.t. the actors parameters.
UVFA
Goal:
HER
Even though an agent may have failed to achieve its given goal in an episode, the agent did learn a sequence of actions to achieve a different objective in hindsight – the state in which the agent finished.
Learning how to achieve different goals in the goal space should help the agent better determine how to achieve the original goal.
Creating a separate copy of the transitions:
that occurred in an episode and replacing
(i) the original goal with the goal achieved in hindsight
(ii) the original reward with the appropriate value given the new goal.

The hierarchical policy is composed of multiple goal-based policies or actor networks.
Experiments
Mujoco physics engine(Todorov et al., 2012)


This Github repository contains the code to implement the Hierarchical Actor-Critic (HAC) algorithm. HAC helps agents learn tasks more quickly by enabling them to break problems down into short sequences of actions. The paper describing the algorithm is available here.
Hierarchical Actor-Critc (HAC)
Code to implement the Hierarchical Actor-Critic (HAC) algorithm Github HAC
https://github.com/andrew-j-levy/Hierarchical-Actor-Critc-HAC-
Learning Multi-level Hierarchies with Hindsight
https://openreview.net/pdf?id=ryzECoAcY7















Download: pdf