Decentralized Stabilization for a Class of Continuous-Time Nonlinear Interconnected Systems Using Online Learning Optimal Control Approach
Decentralized Stabilization for a Class of Continuous-Time Nonlinear Interconnected Systems Using Online Learning Optimal Control Approach
Neural-network-based Online Learning Optimal Control
Decentralized Control Strategy
- Cost functions (critic neural networks) – local optimal controllers
- Feedback gains to the optimal control policies – decentralized control strategy
Optimal Control Problem (Stabilization)
Hamilton-Jacobi-Bellman (HJB) Equations
- Apply Online Policy Iteration Algorithm (construct and train critic neural networks) to solve HJB Equations.
The decentralized control has been a control of choice for large-scale systems because it is computationally efficient to formulate control law that use only locally available subsystem states or outputs.
Though dynamic programming is a useful technique to solve the optimization and optimal control problems, in may cases, it is computationally difficult to apply it because of the curse of dimensionality.
Considering the effectiveness of ADP and reinforcement learning techniques in solving the nonlinear optimal control problem, the decentralized control approach established is natural and convenient.
Notation
: ith subsystem.
: state vector of the ith subsystem.
: local states.
: control vector of the ith subsystem.
: local controls.
: control policies.
: nonlinear internal dynamics.
: input gain matrix.
: interconnected term. Zi(x)‘s x has no i .
: symmetric positive definite matrices.
: nonnegative constants.
: positive semidefinite function.
: positive definite functions satisfying
: control policy.
:
is Lipshcitz continuous on a set
in
containing the origin, and the subsystem is controllable in the sense that there exists a continuous control policy on
that asymptotically stabilizes the subsystem.
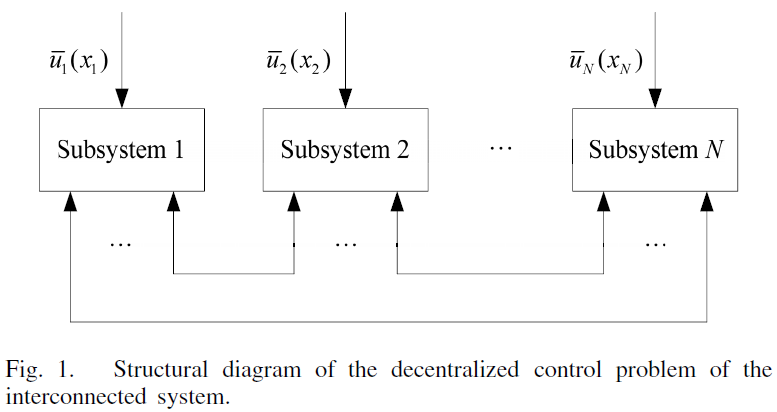
Decentralized Control Problem of the Large-Scale System
Paper studies a class of continuous-time nonlinear large-scale systems: composed of N interconnected subsystems described by
(1)
: initial state of the ith subsystem,
Assumption 1: When , ith subsystem is equilibrium.
Assumption 2: and
are differentiable in arguments with
.
Assumption 3: When , the feedback control vector
.
where
: symmetric positive definite matrices.
are bounded as follows:
(2)
Define
then (2) can be formulated as
C1 – Optimal Control of Isolated Subsystems (Framework of HJB Equations)
C2 – Decentralized Control Strategy
Consider the N isolated subsystems corresponding to (1)
(4)
Find the control policies which minimize the local cost functions
(5)
( How to get the equation 5 ? Should Q = Q and R = P, (Q and P ∈ Lyapunov Equation) ? )
to deal with the infinite horizon optimal control problem.
where
: positive definite functions satisfying
(6)
Based on optimal control theory, feedback controls (control policies) must be admissible , i.e., stabilize the subsystmes on , guarantee cost function (5) are finite.
Admissible Control
Definition 1
Consider the isolated subsystem i,
For any set of admissible control policies , if the associated cost functions
(7)
are continuously differentiable, then the infinitesimal versions of (7) are the so-called nonlinear Lyapunov equations
(8)
( How to get the equation 8 ? Should Q = Q and R = P, (Q and P ∈ Lyapunov Equation) ? )
where
———————————-
Lyapunov Equation
Linear Quadratic Lyapunov Theory
Linear Quadratic Lyapunov Theory Notes
Lyapunov Equation
We assumeIt follows that
. Continuous-time linear systems:
where P, Q satisfy (continuous-time) Lyapunov Equation:
If P>0, Q>0, then system is (globally asymptotically) stable. If P>0, Q≥0, and (Q,A) observable, then system is (globally asymptotically) stable.
where A, P, Q ∈ Rn x n, and P, Q are symmetric
interpretation: for linear system
if
then
i.e., if is the (generalized) energy, then
is the associated (generalized) dissipation
Lyapunov Integral
If A is stable there is an explicit formula for solution of Lyapunov equation:
to see this, we note that
Interpretation as cost-to-go
If A is stable, and P is (unique) solution of
, then
thus V(z) is cost-to-go from point z (with no input) and integral quadratic cost function with matrix Q
If A is stable and Q>0, then for each t, , so
meaning: if A is stable,
- we can choose any positive definite quadratic form
as the dissipation, i.e.,
- then solve a set of linear equations to find the (unique) quadratic form
- V will be positive definite, so it is a Lyapunov function that proves A is stable.
In particular: a linear system is stable if an only if there is a quadratic Layapunov function that proves it.
Evaluating Quadratic Integrals
Suppose is stable, and define
to find J, we solve Lyapunov equation
for P then,
In other words: we can evaluate quadratic integral exactly, by solving a set of linear equations, without even computing a matrix exponential.
———————————-
Online Policy Iteration Algorithm (Critic Networks)
Solve HJB Equations