Meta Learning Shared Hierarchies
Meta Learning Shared Hierarchies
Notation
S: state space.
A: action space.
MDP: transition function P(s’, r|s, a), (s’, r): next state and reward, (s,a): state and action.
PM : distribution over MDPs M with the same state-action space (S, A).
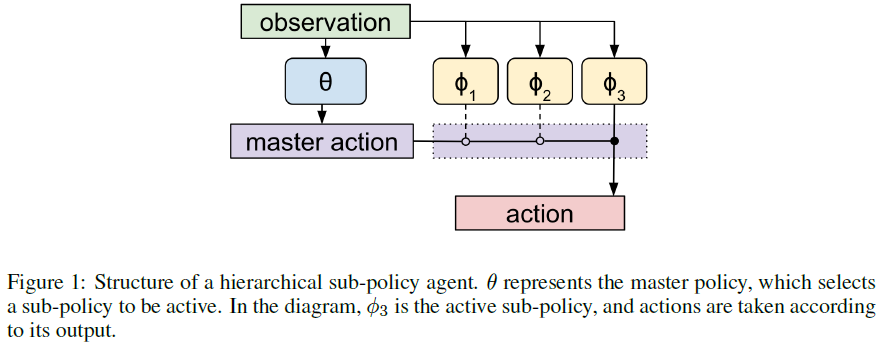
Agent: a function mapping from a multi-episode history (s0, a0, r0, s1, a2, r2, … st-1) to the next action at. iteratively updates a parameter vector (Φ, θ). Agent是映射多个回合的历史到下一个动作的函数。
πΦ,θ(a|s) : policy.
Φ: parameters shared between all tasks.
θ: learned from scratch (从一个0或者随机初始) per-task.
作者的设置是,第一个马尔可夫M来自于PM采样,然后agent是通过分享参数Φ体现,连同随机初始的θ参数。换言之,Φ代表一系列参数,这些参数在tasks之间分享,θ代表一系列每个task里的参数,它是agent在当前task M学习中更新。Agent与task互动T个时间步长,多个回合,收到总的回报R=r0+r1+…+rT-1. 宏观学习目标是优化agent在它的整个生命周期的从采样tasks中的期望回报。
maxΦ EM~PM, t=0…T-1 [R]
θ是某task的master policy,它的动作是从Φk中选择一个k执行动作。简言之:“N选1”。
算法:
-
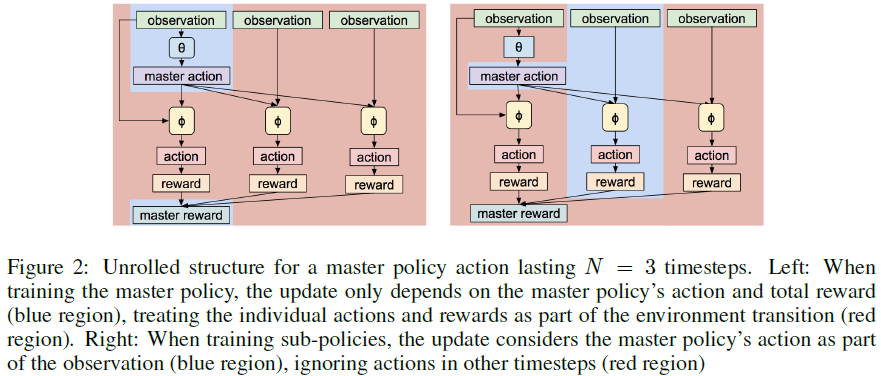
热身阶段:在这个阶段以参数Φ表示的sub-policies不变,从采样的task中,记录用πΦ,θ(a|s)产生的D时间步长的经历。我们从master policy的角度观察这个经历。选择一个sub-policy是(master policy)一个单独的动作,下一个N步长,连同(sub-policy)相应的状态改变和rewards,就是单独的环境转移(也就是说,热身阶段sub-policy对应的状态和reward相对master policy而言就是环境)。更新θ来最大化reward的算法是collected experience along with an arbitrary RL algorithm(例如 DQN, A3C, TRPO, PPO) (Mnih et al., 2015, 2016; Schulman et al., 2015; 2017). 重复W次。 -
联合更新阶段:θ, Φ一起更新。重复U次。收集经历和优化那个在热身阶段定义的θ。同时,复用同样的经历,但是从sub-policies角度看,把master policy看成环境的扩展。master policy的决定就是环境观察的离散部分。对于经历的每N步,我们只要更新master policy激活的那个sub-policy的参数。