Hierarchical Deep Reinforcement Learning: Integrating Temporal Abstraction and Intrinsic Motivation
Hierarchical Deep Reinforcement Learning: Integrating Temporal Abstraction and Intrinsic Motivation
当环境给的奖励少而延迟时,论文给出了一个解决方案:agent至始至终只有一个,但分两个阶段:1总控器阶段,选goal,2控制器,根据当前state和goal,输出action,critic判断goal是否完成或达到终态。重复1,2。总控器选一个新的goal,控制器再输出action,依次类推。我理解它把环境“分”出N个时序上的小环境,与每个小环境对应1个goal。agent实体在这种环境下可以等效为一个点。
The key is that the policy over goals πg which makes expected Q-value with discounting maximum is the policy which the agent chooses, i.e., if the goal sequence g1-g3-g2-... 's Q-value is the maximum value among that of all kinds of goal sequences, the agent should assign goal1 firstly, goal3 secondly, then goal2, ...
以游戏为例:要走很久才能拿到钥匙,拿到钥匙后再走很久开门,所以说环境给agent的奖励少而延迟。
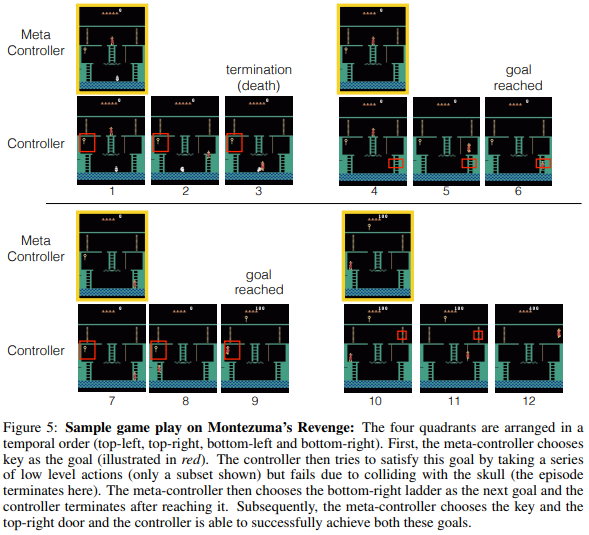
图5
1-3:agent始终只有一个,总控器选goal:钥匙,控制器根据当前位置和钥匙输出动作,下楼梯,往左走,但是碰到骷髅,挂了,critic判断终止。
4-6:总控器选下一个goal:右下梯子,控制器输出动作,agent实体走到右下梯子,critic判断goal达到。
7-9:总控器选下一个goal:钥匙,右上门,控制器输出动作,拿到钥匙,到达右上门,完成goal。
internal critic 以<entity 1, relation, entity 2>形式定义,例如:agent实体 到达 另一个实体 door,用两个实体的相对位置计算二进制reward。
结果:图4表明联合训练阶段的奖励进展——模型开始逐渐学习达到钥匙(+100)和开门(+300)从而获得每个回合大约+400的奖励。
agent首先学习“更简单”goals,比如到达右边的门或中间梯子,然后慢慢开始学习“更难”goals,比如钥匙和底下梯子,这些(更难的goals)可以提供获得更高奖励的途径。
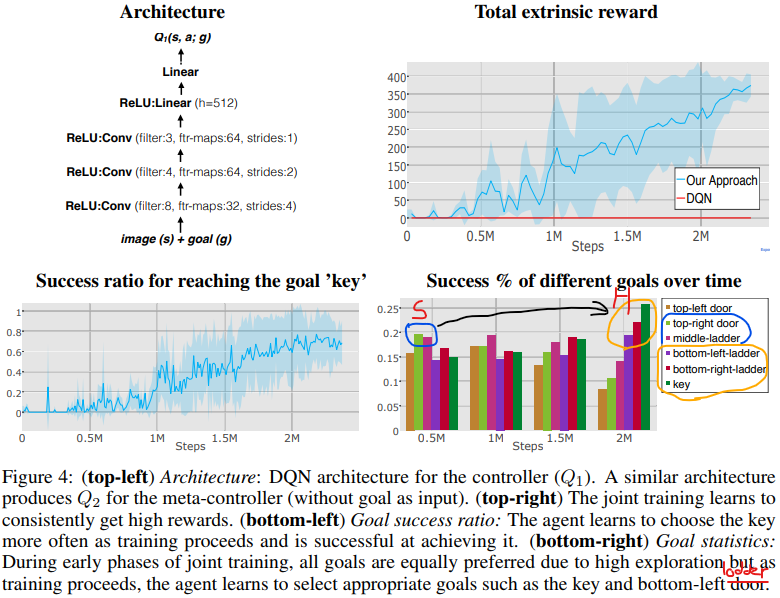
训练结束阶段,我们可以看到:钥匙,底下左梯子,底下右梯子越来越经常地被选择。
Download: pdf