From the last decades of the eighteenth century and for at least a century and a half, Britain and France dominated Orientalism as a discipline. The great philological discoveries in comparative grammar made by Jones, Franz Bopp, Jakob Grimm and others were originally indebted to manuscripts brought from the East to Paris and London. Almost without exception, every Orientalist began his career as a philologist.
Edward W. Said, Orientalism, 1979
Historiographical debates, when they stray beyond the internal logic of the field, generally discuss the social or political relevance of new paradigms or approaches, but rarely do they examine the extent to which our scholarship may be shaped by the institutional makeup of our profession.
Nicholas Barreyre et al., “‘Brokering’ or ‘Going Native’: Professional Structures and Intellectual Trajectories for European Historians of the United States,” American Historical Review 119.3 (2014)
In the historiography of Middle Eastern and Islamic Studies we concentrate on Orientalism and Islamophobia, since self-critique is even harder, when a scholarly discipline feels unfairly singled out and criticized. We are vocal in our critique of Orientalist scholarship which produced the Western mirage of the timeless Orient in the nineteenth century. But we are reluctant to provide further ammunition to those who are already gunning for us, since we are continually confronted with the question of why on earth anyone would study a civilization or a religion that is responsible for …—and everyone will draw on their own experience for the completion of this sentence: terrorism, oppression of women, religious fanaticism, etc. While much research in Middle Eastern and Islamic Studies necessarily focuses on contemporary Muslim societies, I find curious that in the last decade manuscripts and books in Arabic script have begun to attract much more attention. During the last years, François Dèroche, Adam Gacek, and Jan Just Witkam have regularly offered five-day introductions to Islamic codicology in Europe and North America. Historians and literary critics have published studies about Islamic book culture, drawing on statements preserved in literary sources and paratexts, such as ownership statements and reading certificates, though rarely connecting the literary evidence with the material evidence of the manuscripts and printed books themselves (e.g., the Special issue of JAIS 2012 on “The Book in Fact and Fiction in Pre-Modern Arabic Literature”). In research on the history of science, technology, and medicine, the trend is still to explore how a certain intellectual milestone was first reached in Muslim societies before anyone in Christian Europe managed to do so (e.g., the project on “Scientific Traditions in Islamic Societies: Intellectual, Institutional, Religious, and Social Contexts,” McGill University). The follow-up question of what happened to all these grand ideas after their initial conception seems much less popular (e.g., the project of Sonja Brentjes and Jürgen Renn on “Islamicate Transformations of Knowledge,” Max-Planck-Institut für Wissenschaftsgeschichte). Moreover, there is little interest in harnessing the advances in Humanities computing to improve access to this material evidence through the creation of digital catalogs. For the time being, we cannot match literary works with identified copies, whether these are accessible, alleged to be extant, or assumed to be lost, as there is neither a complete inventory of documented works written in a language that uses Arabic script (cf. Leuven Database of Ancient Books), nor a catalog of known copies of manuscripts in Arabic script (cf. Universal Short Title Catalog).
As regards the role of the Digital Humanities in research on the Islamic book, we seem largely content to limit their application to publishing on the Internet, though primarily as digitized book or article, and not as born-digital publication. While many scholars in Middle Eastern and Islamic Studies are maintaining personal websites and weblogs, employing Computer Science to answer research questions need be distinguished from digital publishing on the Internet. Significant resources continue to be dedicated to the production of digital surrogates, and the number of digitized manuscripts and printed books in Arabic script, many of which are available for free on the Internet, is steadily increasing. It is rarely noted, though, that free online access to the digital surrogates of insufficiently cataloged manuscripts and printed books does not automatically make their contents available. The proud press releases are usually very reticent about the indispensable cataloging, which has become a little appreciated and largely ignored activity since Edward Said first associated manuscripts with philology. Nonetheless, the consequences of insufficient cataloging in combination with poor bibliographical reference works are severe and far-reaching. As long as we have at best some random bits of information about some works and their extant copies, we have a very limited grasp of how the works to which we happen to have access are related to the intellectual life of any particular period of Middle Eastern history between the seventh century CE and the present. For example, there is no research on the best practices for assessing survival bias in any corpus of manuscripts or printed books in Arabic script.
Against this backdrop, it seems rather unlikely that in the foreseeable future scholars in Middle Eastern and Islamic Studies will obtain the institutional resources to embark on even one of these cataloging projects, be it the inventory of works or the inventory of their copies, however urgently they are needed. Their coordination will demand not only expertise in Middle Eastern and Islamic Studies but also experience with large-scale Digital Humanities projects and the development of a global network of participating institutions in order to guarantee its financial viability. The funding mechanisms for research in the Humanities in general and in Middle Eastern and Islamic Studies in particular provide few incentives for embarking on such a complex project which will primarily benefit future generations. Aside from the practical challenge that even the most generous grant cycle will be unable to accommodate a decades-long project, whoever will finally manage to embark on either project will probably not live long enough to see it reach maturity.
This dispiriting situation raises the practical question of how to design meaningful research projects that make the most creative use of the already available resources and digital tools. What seems feasible are clearly limited studies that examine Islamic books in synchronic and diachronic contexts. Synchronic projects would focus on book production in order to establish criteria for the cataloging of both the literary works and their material support, whether they are manuscripts or printed books, while diachronic projects would trace the circulation and reception of a range of literary works in Arabic and Persian from the Abbasid era (750-1258 CE) to the present. Both types of project necessitate the codicological analysis of manuscripts and bibliographical research on printed books, so that the project outcomes should combine the publication of a study, whether a book or an article, with an online depository for the accumulated codicological and bibliographical data. To establish these new publication standards for research about manuscripts and printed books in Arabic script could perhaps even serve as the first baby step towards the organization of an inventory of either works or copies, if scholars working on related subjects agree to contribute their codicological and bibliographical data to a shared Open-Access depository (cf. Open Context which organizes the review, documentation, and Open-Access publication of primary data in cultural heritage related fields).
PS – On 7 July 2014, Nur Sobers-Khan and Ursula Sims-Williams published their post about “A Newly Digitised Unpublished Catalogue of Persian Manuscripts” on the Asian and African Studies Blog of the British Library (BL). The draft of of the never completed third volume of the Catalogue of the India Office Library‘s Persian manuscript collection, written by C. A. Storey (1888-1968), Reuben Levy (1891-1966), and A. J. Arberry (1905-1969), is now available as a digital surrogate on the BL’s website (Mss Eur E207/1-38). The unit of digitization is the individual page, and it is impossible to use full-text search for finding information about particular works or specific copies. In their blog post, the authors explain which indices are available and how the catalog’s 38 separate folders can be browsed by topic or searched by call number.
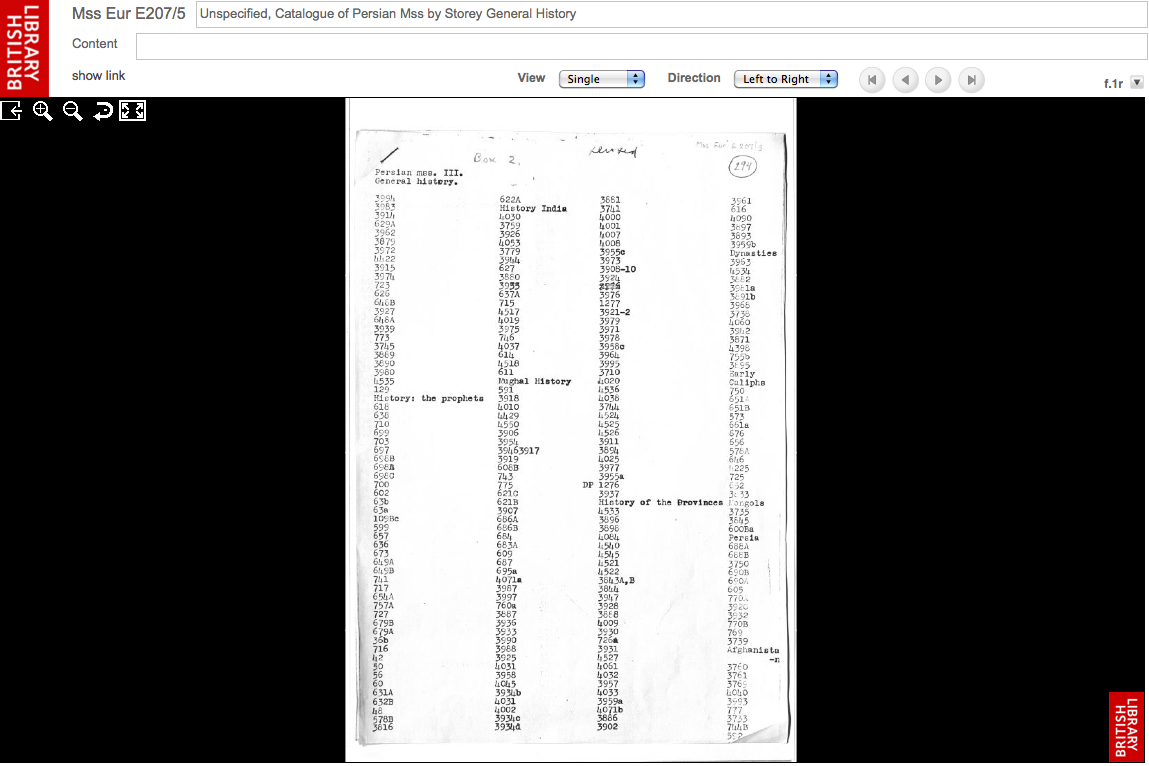 Partial subject index to folders 5-9, History, by C. A. Storey.
Partial subject index to folders 5-9, History, by C. A. Storey.
London, British Library, Mss Eur E207/5, fol. 1a,
available at: https://www.bl.uk/manuscripts/Viewer.aspx?ref=mss_eur_e207!5_f001r.
Screen capture, 9 July 2014.
 C. A. Storey’s notes about MS pers. India Office Islamic 3739.
C. A. Storey’s notes about MS pers. India Office Islamic 3739.
London, British Library Mss Eur E207/8, fol. 75a,
available at: https://www.bl.uk/manuscripts/Viewer.aspx?ref=mss_eur_e207!8_f075r.
Screen capture, 9 July 2014.
The decision of the British Library to rather obtain a grant for the creation of 3,778 digital images suggests that British manuscript curators did not consider it feasible to integrate these draft descriptions into Fihrist, the British union catalog for manuscripts in Arabic script.
Updated, 9 July 2014
Corrected, 6 August 2014