Nomenclature has proved a difficult problem, for two reasons. First, the style of both subjects changed three times during the course of their lives, from plain Lindsay, to Lord Lindsay, and finally Earl of Crawford. […] The second difficulty is the shortage of Christian names in the Lindsay family, James, Hugh, Alexander, Charles (and recently David) are recurrent names, born by several Lindsays in the period 1812-1913.
Nicolas Barker, Bibliotheca Lindesiana: The Lives and Collections of Alexander William, 25th Earl of Crawford and 8th Earl of Balcarres, and James Ludovic, 26th Earl of Crawford and 9th Earl of Balcarres, 1978.
[T]he respect for early books which is now taken for granted is a fairly recent development. Vast numbers of books have perished utterly and books which are described in old lists and catalogues may no longer exist. Many collections of the past are no longer reconstructable. A separate kind of problem […] centres round the extent to which owners have marked their books. […] Although many owners have marked their books, for reasons of security, vanity, or both, many more have not, and countless books have passed through various hands without being marked in any way. This applies not only to people who owned only one or two books, but also to substantial collectors. […] This problem generates two obvious consequences. Firstly, there must be book owners of the past, and possibly quite major collectors, whose identity will never be known because their libraries were dispersed without a surviving record and the books were unmarked. Secondly, we may be able to identify people who are likely to have had appreciable libraries, but be unable to confirm one way or the other the influence which personal book ownership had on their activities, as their books cannot be identified even if they still exist.
David Pearson, Provenance Research in Book History, 1st ed., 1994.
Serendipity is always a factor in research, as is a scholar’s ability to recognize and seize an opportunity. In 1958, a few years after the Egyptian Revolution of 1952, the government of communist Czechoslovakia appointed the Arabist Rudolf Veselý (1931-2020) to teach Czech at the Higher School of Languages in Cairo. Until 1964, when he had to return to Prague for good, Veselý managed to research late Mamluk, early Ottoman history in the Egyptian archives, since he enjoyed, as an employee of the new Egyptian government, very generous access. Immersed into these mostly unexplored riches, Veselý became an expert of Arabic chancery and legal documents, while writing his dissertation about a waqf from sixteenth-century Cairo (Dr. phil. Charles University, Prague 1966). In the 1970s and 80s, Veselý’s academic career stalled in communist Czechoslovakia; nevertheless, he continued with his research about medieval Islamic archives. After the Velvet Revolution of 1989, Veselý was eventually appointed professor of Middle Eastern history and culture at his alma mater.
In the 1970s and 80s, Veselý’s German colleague Rudolf Sellheim (1928-2013), professor of oriental studies at the University of Frankfurt (1958-1994), was working with uncatalogued holdings of the State Library in West Berlin (Staatsbibliothek zu Berlin SBB). Sellheim noticed on the title page of a fragment of Rāzī’s commentary on the first volume of Ibn Sīnā’s Qānūn fī al-ṭibb the name Muḥammad b. Muḥammad b. al-Qūṣūnī in an ownership note, dated to the beginning of 947 [ began 8 May 1540 ].
SBB Ms. or. oct. 1466, fol. 1a
Fakhr al-Dīn Rāzī (1149-1210), Sharḥ kulliyyāt al-qānūn fī al-ṭibb
h = 21 cm, incomplete, colophon dated mid Shaʿban 627 [ end of June 1230 ]
purchased from Isaac Benjamin Yahuda (1863-1941) in 1913 (SBB acc. no. 1913.128)
digital surrogate: http://resolver.staatsbibliothek-berlin.de/SBB0001FA7300000000
Public Domain Mark 1.0
Qalamos entry: https://www.qalamos.net/receive/DE1Book_manuscript_00017885


There were three well-known physicians with the name Muḥammad al-Qūṣūnī, also al-Qawṣūnī: father, son, and grandson. The al-Qūṣūnī family had come to prominence in fifteenth-century Cairo. From the early sixteenth century until the early seventeenth century, several of their men served as physicians at the Ottoman court, and at least two died in Istanbul. In Ottoman sources the family became known as Qayṣūnī-zāda, though it is not clear whether there ever was an Istanbul branch. In contrast, the family’s Cairo branch is documented until the second half of the seventeenth century. Between the fifteenth and the seventeenth century, other men of the al-Qūṣūnī family were also named Muḥammad. While the al-Qūṣūnī family included distinguished physicians, members of this family were active in other professions as well.
The father’s full name was Shams al-Dīn Muḥammad b. ʿAbd al-Wahhāb al-Qūṣūnī (1430-1511). He served at the time of his death as a personal physician of al-Ashraf Qānsūh al-Gūrī (r. 1501-1516) at the Mamluk court.
The son’s full name was Shams al-Dīn Muḥammad b. Muḥammad al-Qūṣūnī al-Nāṣirī (d. 1524). He had worked, like his father, as a physician at the court of Qānsūh. After the Ottoman victory over the Mamluk army near Aleppo, the Ottoman troops took Shams al-Dīn prisoner. In early 1517, he joined the entourage of Selim I (r. 1512-1520), and worked around 1520 at the Ottoman court in Istanbul. He died in Egypt, in Rosetta. However, his brother Sayyidī ʿAlāʿ al-Dīn ʿĀlī b. Muḥammad al-Qūṣūnī became the physician-in-chief at the Ottoman court, and died in Istanbul in 1548.
The grandson’s full name was Badr al-Dīn Muḥammad b. Muḥammad b. Muḥammad al-Qūṣūnī al-Ḥānafī; also known as Ibn al-Qūṣūnī and Qīṣūnī -zāda (1514-1568). Due to a mix-up of proper names (Arabic sing. ism), in some Ottoman sources he is called Maḥmūd al-Qūṣūnī (Sellheim, Materialien zur Literaturgeschichte, 1: 205). He was educated in Cairo. In 1547, Badr al-Dīn successfully treated Beyazid, the governor of Anatolia and a son of Suleyman (r. 1520-1566), and the following year, the sultan appointed him as his personal physician. Badr al-Dīn joined Suleyman’s Safavid campaign, and in 1549 he became a member of the Ottoman court in Istanbul. Badr al-Dīn eventually served, from 1562 until his death in Istanbul, as the court’s highest ranking physician, first to Suleyman and then to his successor Selim II (r. 1566-1574). Badr al-Dīn had a son named Muḥammad, though nothing further is known of him.
As these three physicians are easily mixed up (e.g., the references to Muḥammad al-Qūṣūnī III in Shefer-Mossensohn, Ottoman Medicine, 2010, index), Sellheim added to his catalogue entry (VOHD 17, A, 1, 55 = Materialien zur Literaturgeschichte, 1: 201-203 s.v. no. 55 and pl. 16, fig. 17) an excursus, for which he compiled biographical details scattered across a wide range of literary sources: “Zur Familie al-Qūṣūnī” (Materialien zur Literaturgeschichte, 1: 203-213). To clearly distinguish the three men from each other, Sellheim numbered them Muḥammad al-Qūṣūnī I (d. 1511), Muḥammad al-Qūṣūnī II (d. 1524), and Muḥammad al-Qūṣūnī III (d. 1568). Sellheim’s original essay was published in 1976. His investigation had become feasible, since by the 1970s, new scholarship about the history of medicine in Muslim societies had facilitated access to both medical literature and physicians’ biographies. Details for the life and work of Muḥammad al-Qūṣūnī III – a high-ranking court physician serving not just one, but two sultans in Istanbul – could now be gleaned from sixteenth-century Ottoman sources. In 1987 Sellheim’s subsequent discoveries about the al-Qūṣūnī family were published in the “Nachträge und Berichtigungen” of his 1976 catalogue of SBB manuscripts (Materialien zur Literaturgeschichte, 2: 111-112 = VOHD 17, A, 2, pp. 111-112).
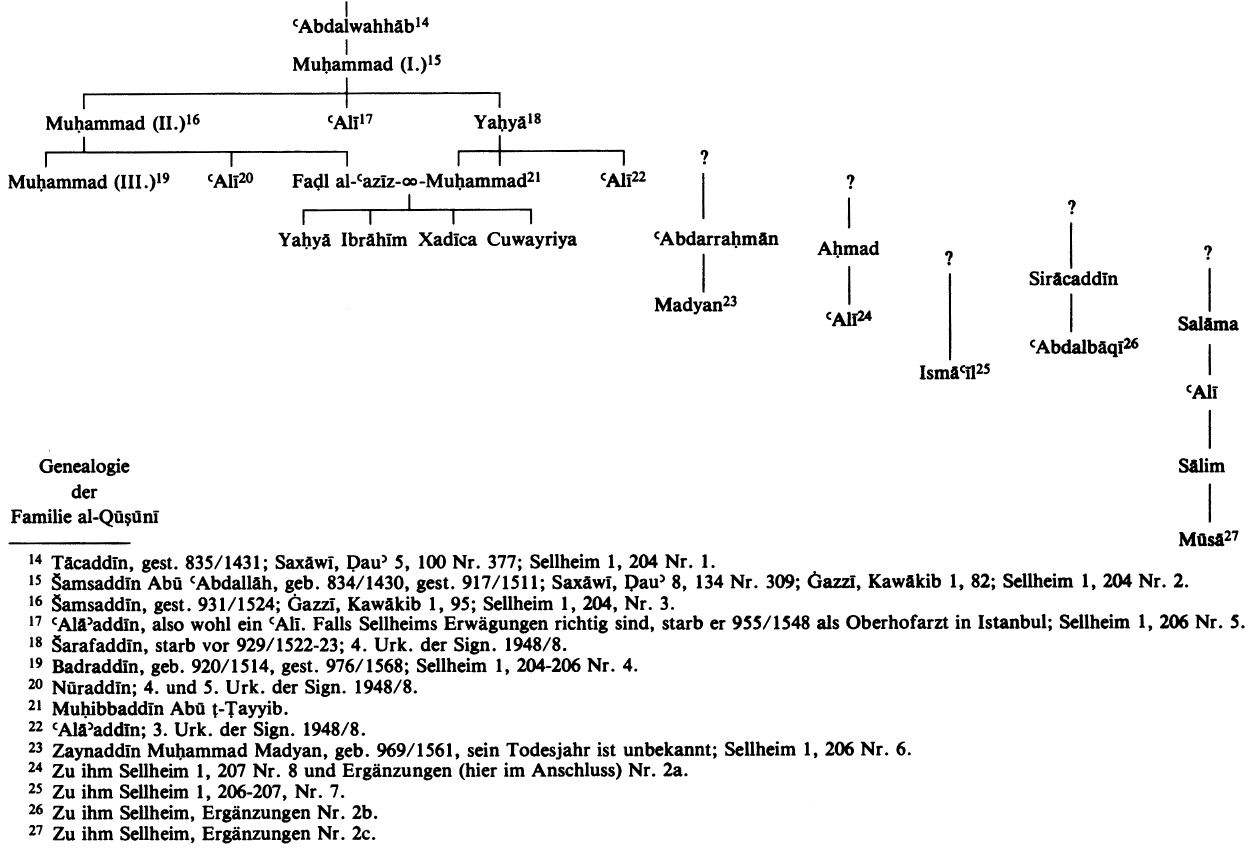
In 1992, an updated version of the excursus was published in Oriens (33: 441-444) – as the journal was still edited by Sellheim in Frankfurt. It was presented as an appendix (“Ergänzungen”) to an article by Veselý about “Neues zur Familie al-Qūṣūnī: Ein Beitrag zur Genealogie einer ägyptischen Ärzte- und Gelehrtenfamilie” (33: 437-440). During his 1960s dissertation research in Cairo, Veselý had discovered a waqfiyya (dated 1528) and five slightly earlier rental contracts. Taken together, these six archival documents yielded new details about the al-Qūṣūnī family in the early sixteenth century. Notwithstanding the synergy between their sources, Veselý and Sellheim stressed the fragmentary state of their knowledge, as the genealogy of the al-Qūṣūnī family continued to be constructed from biographical “membra disiecta” (p. 437) which could not always be linked to each other (p. 441: “Leider reicht der Name seines verstorbenen Vaters Aḥmad nicht aus, um den Anschluss an andere, uns bekannte Mitglieder der Qūṣūni-Familie herzustellen”). Although the archival documents filled some gaps in the family tree, which was first constructed by Sellheim in 1976 (Materialien zur Literaturgeschichte, 1: 203, diagram 13), missing connections remained in Veselý’s revised and annotated family tree (p. 440):

There is, however, a subtle difference with regard to how Veselý and Sellheim approached the ownership note in the Rāzī fragment (SBB Ms. or. oct. 1466), which had prompted Sellheim’s interest in the al-Qūṣūnī family. The owner just stated name and date:
malaka-hū
Muḥammad b. Muḥammad b. al-Qūṣūnī
awwal sanat
947
Muḥammad b. Muḥammad b. al-Qūṣūnī
acquired it [i.e., the manuscript ]
at the beginning of the year
947
The bare-bones inscription is unremarkable, as no additional, identifying elements – be it a place name, be it a laqab, shuhra, or kunya – are required whenever an owner bothers – for their own private reasons – to write their name into a book. It is after all just a book. It might have been considered valuable, but really, so what? How much care did people take, somewhere in the Eastern Mediterranean in 1540, when they scribbled their names into 300 year old literary fragments? In the end, ownership notes are individual expressions, they are not legal documents. For Veselý the ownership note proved that in 1540 the Rāzī fragment had been property of the al-Qūṣūnī family (p. 436: “die Familie al-Qūṣūnī, in deren Besitz sich die Handschrift i.J. 947/1540 befand”), and there he stopped. Because of his research in the Egyptian archives, Veselý (“Hauptprobleme der Diplomatik:” 340) was familiar with the naming conventions according to which people identified themselves in contemporary legal documents. In contrast, Sellheim (Materialien zur Literaturgeschichte, 1: 202) read the name in the ownership note as ending with Ibn al-Qūṣūnī, and thus identified Muḥammad al-Qūṣūnī III as the person who wrote his name into the Rāzī fragment in 1540.
At this point – without a thorough investigation of all references collected by Sellheim and Veselý – I am aware of two more manuscripts with ownership notes signed by an Ibn al-Qūṣūnī: an early twelfth-century copy of al-Ḥarīrī’s al-Maqāmāt in the Istanbul University Library (İstanbul Üniversitesi Kütüphanesi İÜK) and a fifteenth-century excerpt from Ibn Taghrībirdī’s Mawrid al-laṭāfa in the Gotha Research Library (Forschungsbibliothek Gotha FBG) of the University of Erfurt.
İÜK Ms. A 4566, fol. 1a
al-Ḥarīrī (1054-1122), al-Maqāmāt
h = 21 cm, complete, no date
contested authorial ijāza dated Muḥarram 514 [ began 2 April 1120 ]
first published by Ritter, ”Autographs:” 68-69 and pl. IV
description in MacKay, “Certificates of Transmission:” 28 and 72 fig. 23
for the authenticity of the ijāza, see Keegan, “Commentators,” 295 note 2
for the ownership note, see Sellheim, Materialien zur Literaturgeschichte, 2: 111
![]()
This ownership note is dated 953 [ began 4 March 1546 ]:

FBG Ms. orient. A 1626, fol. 1a
Ibn Taghrībirdī (1411-1469), Mawrid al-laṭāfa
h = 22 cm, excerpt, no date
purchased by Ulrich Jasper Seetzen (1767-1811)
image courtesy of the Gotha Research Library of the University of Erfurt
Public Domain Mark 1.0
I am much indebted to the generous help of Feras Krimsti, the FBG’s Curator of the Oriental Manuscript Collection
description in Pertsch, Die arabischen Handschriften, III, 3, 1881, pp. 242-243
Qalamos entry: https://www.qalamos.net/receive/DE39Book_manuscript_00001632

The ownership note has a Qalamos entry: https://www.qalamos.net/receive/DE39SecEntry_secentry_00001065
which reads the name as Muḥammad b. Muḥammad al-Qūṣūnī – without the second “ibn” – and identifies Muḥammad al-Qūṣūnī III as the owner.
The ownership note is dated 941 [ began 13 July 1534 ]:

The most surprising aspect of these three ownership notes, which otherwise appear as almost uncannily uniform, is the variant spelling of the numeral 4 in the dates 947/1540 (SBB Ms. or. oct. 1466) and 941/1534 (FBG Ms. orient. A 1628). As they are informal short writing samples, they do not allow for any sustained paleographical argument about the evolution of a person’s handwriting. Regrettably, the manuscript in Istanbul is of no help, as it is dated 953/1547.
The fundamental challenge for the interpretation of ownership notes is the tension between consistency and variance. Without unchanging characteristics it is impossible to identify hands. Conversely, the possibility of seemingly random changes is always a convenient argument, whenever ownership notes could be assigned to already identified book owners.
Thanks to the continuing digitization of manuscripts in Arabic script, it is possible to compare Sellheim’s reading of the two ownership notes in SBB Ms. or. oct. 1466 and İstanbul Üniversitesi Kütüphanesi MS. A 4566 with an ownership note signed by a Muḥammad b. Muḥammad al-Qūṣūnī which has survived in a much damaged Dioscorides fragment in the Bologna University Library (Biblioteca Universitaria di Bologna BUB). The fragment’s origins are obscure, and almost nothing is known about its circulation in the Eastern Mediterranean and southeastern Europe until 1702, when its presence in the Habsburg empire is suddenly documented. Drawing on the dated colophon and an art-historical analysis of its illustrations, Anna Contadini has suggested that the manuscript was produced by an Ayyubid court workshop in Syria around 1240.
BUB Ms. 2954, fol. 274b
Kitāb Dīyusqūrīdis al-ḥakīm
h = 35 cm, incomplete, scribal note dated 17 Dhū al-ḥijja 642 [ 16 May 1245 ], with botanical illustrations and a portrait of Dioscorides with Luqmān and Aristotle
description published in 1702 in the library catalogue of Luigi Fernando Marsili FRS (1658-1730): Talman, Elenchus, 4: 14-16 s.v. no. 4
digital surrogate: http://hdl.handle.net/20.500.14008/78130
Creative Commons license BY-NC-ND 4.0
art-historical discussion in Contadini, “Ayyubid Illustrated Manuscripts,” 186-187 with pls. 9.8-9.9
description in Machaeva, Catalogo, 206–210 s.v. no. 80; she reads al-Mawṣūlī, and not al-Qūṣūnī

Since the ownership note is dated 924 [ began 13 January 1518 ], it could not have been written by Muḥammad al-Qūṣūnī III, who was born in 1514. Applying Occam’s razor, the ownership note would be associated with Muḥammad al-Qūṣūnī II. His full name was Muḥammad b. Muḥammad al-Qūṣūnī, and in 1518, shortly after the collapse of the Mamluk sultanate, he was a prominent physician who had managed to move from an official position at the Mamluk court to one at the Ottoman court.

In the second line, the name “Muḥammad” was separated, by lifting the pen, from the following “ibn”, abbreviated to a single stroke. The ownership note is furthermore distinguished by its vocabulary and its placement within the codex. As regards its language, this ownership note is literally an ex libris:
min kutub
Muḥammad b. Muḥammad al-Qūṣūnī < laṭafa bi-hī ? >
ʿām
924
from the books of
Muḥammad b. Muḥammad al-Qūṣūnī < may [ God’s ] kindness be with him ? >
the year
924
Whereas the other five ownership notes are placed at the beginning of the work, in the Bologna Dioscorides the ownership note was written next to the colophon, at the end of the work (fol. 274b). Unfortunately, in its current state, the manuscript lacks the opening leaves. As it is impossible to determine whether in 1518, the volume still included a title page, this observation – though noteworthy as a codicological detail – is a dead end.
The Bologna Dioscorides reveals the limits of an ownership note’s evidentiary value in other ways as well. Once it has been successfully argued that an identified person could have owned a certain manuscript at a particular point in time, this detail needs to be contextualized in order to become meaningful for research about the transmission of knowledge in Muslim societies. It feels of course good – as it is intellectually plausible and emotionally satisfying – to have determined that in the early sixteenth century a thirteenth-century Dioscorides fragment was probably owned by the prominent physician Muḥammad al-Qūṣūnī II. Setting aside the inconvenient fact that the ownership of manuscripts with medical and pharmaceutical literature has never been restricted to physicians or pharmacists, the successful identification of a historical person who could have owned a manuscript without any documentation of its origins and provenance, becomes an open invitation to further speculation in the hope of uncovering additional possibilities about this manuscript’s circulation. In the case of the Bologna Dioscorides, the manuscript’s plausible association with Muḥammad al-Qūṣūnī II allows for many scenarios to be imagined, as very few details about his life are reliably documented – there is not even an estimated year of his birth. Yet none of these scenarios, however lovingly they are supported with reasonable assumptions, changes the reality that for the time being it is impossible to know as to where – Egypt, Syria, Turkey, or Fertile Crescent? – and how – loot, purchase, gift, or giveaway? – Muḥammad al-Qūṣūnī II might have gotten his hands on this volume, and what he subsequently did with it. The ownership note only proves that in 1518 a Muḥammad b. Muḥammad al-Qūṣūnī wrote his name into this Dioscorides fragment. Historians, following Veselý’s model of careful close reading, may eschew all speculations by limiting themselves to this fact: in 1518 the al-Qūṣūnī family owned the Bologna Dioscorides.
Two further examples illustrate different interpretative approaches to two dated ownership notes which are even more ambiguous, because the owners identified themselves as Muḥammad al-Qūṣūnī. Since their notes were left in undated manuscripts, there is an even stronger incentive to identify the men whose notes establish a terminus ante quem for these codices. One is a fragment of a Mamluk biographical dictionary, also kept in Gotha, and the other is a short commentary on al-Jaghmīnī’s widely used introduction to astronomy, held in the Cadbury Research Library (CRL) of the University of Birmingham. The author of the commentary has yet to be identified.
FBG Ms. orient. A 1758, fol. 1a
Ibn Rāfiʿ al-Sallāmī (1305-1372), Kitāb al-wafayāt
h = 18 cm, complete, no date
purchased by Ulrich Jasper Seetzen (1767-1811) in Cairo in 1808
digital surrogate: https://dhb.thulb.uni-jena.de/receive/ufb_cbu_00005177
Public Domain Mark 1.0
I am much indebted to the generous help of Feras Krimsti, the FBG’s Curator of the Oriental Manuscript Collection
description in Pertsch, Die arabischen Handschriften, III, 3, 1881, pp. 338-339
Qalamos entry: https://www.qalamos.net/receive/DE39Book_manuscript_00001764

The ownership note has a Qalamos entry: https://www.qalamos.net/receive/DE39SecEntry_secentry_00001065
which reads the name as Muḥammad al-Qūṣūnī and identifies Muḥammad al-Qūṣūnī III as the owner.
The ownership note is dated 940 [ began 23 July 1533 ]:

malaka-hū
Muḥammad al-Qūṣūnī
sanat
940
Muḥammad al-Qūṣūnī
acquired it [i.e., the manuscript ]
the year
940
CRL Mingana Collection, Ms. Islamic Arabic 259, fol. 1a
Jalāl al-Dīn Faḍl Allāh al-ʿUbaydī [unidentified], Khāshiyya ʿalā al-Jaghmīnī
h = 18 cm, no date [c.1350?], with astronomical diagrams
previously owned by Alphonse Mingana (1881-1937)
I am much indebted to the generous help of Mark Williams, the CRL’s Assistant Public Service Manager
description in the Catalogue of the Mingana Collection of Manuscripts, 4, 1985, no. 943
Fihrist entry: https://www.fihrist.org.uk/catalog/manuscript_3814
The ownership note – regrettably I do not have a publishable image – has a Fihrist entry: https://www.fihrist.org.uk/catalog/person_f2613
which does not attempt any identification of this Muḥammad al-Qūṣūnī.
The ownership note was added to fol. 1a, which in this codex is a cover page, and not a title page.
The note is dated 971 [ began 21 August 1563 ]:
malaka-hū
Muḥammad al-Qūṣūnī
laṭafa Allāh bi-hī wa-bi-al- < muslimīn ? >
fī sanat
971
Muḥammad al-Qūṣūnī
acquired it [i.e., the manuscript ]
may God’s kindness be with him and the < Muslims ? >
in the year
971
These two ownership notes were written about 30 years apart: the one in FBG Ms. orient. A 1758 is dated 940/1533, and the other in CRL Mingana Ms. Islamic Arabic 259 is dated 971/1563. Because of this time gap it is more difficult to confidently conclude that they were written by the same man, even though both were written by a Muḥammad al-Qūṣūnī, and both use the “malaka-hū” phrase. According to the available cataloguing, the CRL’s collections do not include another manuscript with a Muḥammad al-Qūṣūnī ownership note. As methodologically a hapax legomenon is a freak incident that cannot be contextualized, his identification was not attempted. In contrast, Gotha has two Muḥammad al-Qūṣūnī ownership notes, and in this case, the men signed with different names, but the “malaka-hū” phrase is identical, and these notes were written about the same time, around 940-941/1533-1535. (As I have not seen the original manuscripts, I am following the cataloguers who read the middle numeral in both dates as a 4.) Moreover, both manuscripts contain works of Mamluk historiography.
FBG Ms. orient. A 1626, fol. 1a detail
FBG Ms. orient. A 1758, fol. 1a detail
The cataloguer assigned these two notes to the same person: Muḥammad al-Qūṣūnī III, who was born in 1514 and therefore could have written these notes as a young man in Cairo. It is an elegant solution. Applying again Occam’s razor, what would be the probability that around 1534, two different men with the same ism and the same nisba wrote their versions of their names into manuscripts with works about the pre-Ottoman history of Egypt? Unfortunately, the geographer Ulrich Jasper Seetzen (1767-1811) did not note down the acquisition details of both volumes: he purchased FBG Ms. orient. A 1758 in Cairo in 1808; neither date nor place of purchase was recorded for FBG Ms. orient. A 1628. Between 1803 and his death in Yemen in 1811, Seetzen had travelled widely in the Arab lands, with extended stays in Aleppo, Damascus, and Cairo, and thus it is impossible to confirm whether Seetzen might have bought both manuscripts in Cairo. Considering the research of Sellheim and Veselý about the al-Qūṣūnī family, while accounting for the popularity of the ism Muḥammad, I would be more comfortable with limiting myself to the only knowable fact: members of the al-Qūṣūnī family owned these codices around 1534. I hasten to add that I do understand how unsatisfactory such a parsimonious inference feels.
As it is impossible to identify with a modicum of reliability the individual men who used, with variations, the name Muḥammad al-Qūṣūnī in six ownership notes, which other insights can be gleaned – while keeping in mind that six is too small a number for any momentous conclusions – from these notes and their manuscripts? Thinking about these manuscripts as books associated with different members of a family of scholars and physicians made me curious about their contents: Which texts did they own and, perhaps, even read? The first four are canonical works of pharmacology, medicine, astronomy, and Arabic adab literature, whereas the last two belong to the historiographical literature of the Mamluk era. None of the six manuscripts contains a contemporary work, written in the sixteenth century.
-
- anonymous Arabic adaptation of Dioscorides’ materia medica (colophon dated 1240), incomplete
- Fakhr al-Dīn Rāzī’s commentary on Ibn Sīnā’s Qānūn fī al-ṭibb (colophon dated 1230), fragment
- unidentified commentary on Jaghmīnī’s introduction to astronomy (no date), complete
- al-Ḥarīrī’s al-Maqāmāt (no date, ijāza dated 1120), complete
- Ibn Rāfiʿ al-Sallāmī’s biographical dictionary regarding Hadith scholarship in fourteenth-century Egypt (no date), complete
- one of Ibn Taghrībirdī’s Mamluk chronicles (no date), excerpt
The present state of research does not allow for assessing the value of these manuscripts in the used-book trade and among collectors in sixteenth-century Cairo or Istanbul. However, approaching them as intergenerational family property reveals two elements which are conspicuously absent: none carries a second ownership note written by another member of the al-Qūṣūnī family, and none preserved any traces of ever having been part of a library funded by a waqf, be it an endowment of the al-Qūṣūnī family or of someone else. While it remains of course impossible to base any argument on that which is not there, identifying absences illuminates areas of ignorance. The manuscripts’ silence about passing on books within the al-Qūṣūnī family feels particularly salient with regard to the Dioscorides fragment (BUB Ms. 2954), since it belongs to the corpus of highly valued late Abbasid, early Ilkhanid large-format manuscripts with illustrations, which for lack of a better label are still occasionally called “Arab painting”.

BUB Ms. 2954, fols. 130b-131a
The Dioscorides fragment is not the oldest of the six manuscripts, but it preserves the oldest ownership note. As mentioned above, it is practically impossible that this note, dated 924/1518, was written by Muḥammad al-Qūṣūnī III, as he was born in 1514. It would have made for a nice family anecdote if Muḥammad al-Qūṣūnī II, a well-known physician who died six years later, in 1524, had bequeathed an almost three-hundred year old illustrated fragment of a famous materia medica handbook to his young son, Muḥammad al-Qūṣūnī III, who in turn would become an even more successful physician.
In her 2018 study of Teaching and Learning the Sciences in Islamicate Societies: 800-1700, Sonja Brentjes emphasized the diversity of formal and informal educational opportunities in premodern Muslim societies vis-à-vis the limited evidence explored in contemporary research. She observed that the Islamic sources do not seem to support the received wisdom that medical training was primarily passed on within families (pp. 131-134). In Mamluk Egypt, for example, physicians’ biographies seem to regularly list teachers and mentors who were not family members. With regard to the continuous circulation of canonical textbooks, she warned of projecting our own historical interests unto the early modern era, as large numbers of extant science manuscripts document how teachers routinely designed customized textbooks for their students (pp. 225-226, cf. pp. 247-254 for medical literature).
Brentjes wrote this study in the 2010s, drawing on biographical dictionaries, catalogues, and manuscripts, when Middle Eastern studies at large began to vigorously embrace codicology and book history. Although in fields such as the history of science, scholars have always heavily depended on manuscripts as many of their source are not available in printed versions, the materiality of the manuscripts themselves has usually remained invisible as they were perceived as mere media – that is: transparent containers – for the transmission of knowledge. In contrast, Brentjes’ study includes reproductions of manuscript pages – though no list of illustrations or figures – and references to specific manuscripts (for call numbers, see p. 289). Even more importantly, she acknowledged the practical difficulties of understanding how a certain manuscript was employed for the transmission of knowledge (p. 252).
Among professionals like the educated members of the al-Qūṣūnī family, books must have been everywhere – like air – because Islam – like Judaism and Christianity – had emerged in the literate societies of Late Antiquity as a civilization that depended on the written transmission of knowledge. In literate societies, book ownership appears to be self-explanatory, even though ownership notes often reveal very little about a book’s meaning, value, or provenance despite the tantalizing specificity of individual names and precise dates. For book historians, the methodological challenge of investigating book ownership concerns the question of how to establish meaningful differences between the access to books for work, leisure, or religious practice; the individual or institutional ownership of books on purpose or by chance; and the intentional collecting of books for a particular goal. As Meredith Quinn observed in her dissertation (Harvard University 2016) about the book culture of seventeenth-century Istanbul: “people from every segment of society came into contact with books and the texts they contained” (p. iv). And yet, very few people actually owned any books, and not every person or institution that owned a few books thought of their books as a clearly defined collection or even a formal library.
I will conclude this reflection on the evidentiary value of ownership notes with a discussion of a medical manuscript that in its current state is associated with two physicians of the al-Qūṣūnī family, though not through straightforward ownership notes. The dual connection was discovered by Cécile Bonmariage, professor of Islamic philosophy at the Université catholique de Louvain. In the late 2000s, when she worked for Princeton University Library (PUL) as a cataloguer of Don Skemer’s Islamic Manuscripts Cataloging and Digitization Project (https://dpul.princeton.edu/islamicmss/about/islamic-manuscript-collections), Bonmariage noticed that a formal copy of a popular commentary about al-Lamḥa al-ʿafīfiyya fī al-ṭibb by Ibn Amīn al-Dawla (active 15th century) mentioned Muḥammad al-Qūṣūnī I (1430-1511) on the undated title page and ended with a reading note by the physician Zayn al-Dīn Abū al-Ṣalāḥ Muḥammad Madyan b. ʿAbd al-Raḥmān al-Qūṣūnī (b. 1561, d. after 1634). His precise position within the genealogy of the al-Qūṣūnī family cannot be determined, because the name of his paternal grandfather has not been transmitted (Sellheim, Materialien zur Literaturgeschichte, 1: 206 s.v. 6). The loss of this detail about Madyan’s immediate male ancestors is baffling, as he included an entry about himself into his biographical dictionary of physicians. Unlike his relatives with the very popular ism Muḥammad, he did not use the nisba al-Qūṣūnī in his ownership notes and instead identified himself as Madyan al-ṭabīb (e.g., PUL Isl. Mss. Garrett 567 H and Garrett 2315 Y). In 2009 Bonmariage published an article about “Un nouvel élément à propos des Qūsūnī” in Arabica (56: 269-273), continuing the research of Sellheim and Veselý about the al-Qūsūnī family. Like the publications of Sellheim and Veselý, Bonmariage’s article followed a serendipitous encounter with a manuscript.
PUL Islamic Mss. Garrett 570 H
Maḥmūd b. Aḥmad al-ʿAyntābī, also known as Ibn al-Amshāṭī (1409-1496), Kitāb taʾsīs al-ṣiḥḥa bi-sharḥ al-Lamḥa
h = 27 cm (cropped as there are cut off marginal comments), composite codex
Martijn Theodoor Houtsma (1851-1943) bought the manuscript from Amīn b. Ḥasan al-Ḥulwānī al-Madanī (d. 1898) in the early 1880s
Robert S. Garrett (1875-1961) purchased the codex in 1900 as part of a collection which Brill was selling on Houtsma’s behalf
Gift of Robert Garrett, Class of 1897, to Princeton University in 1942
digital surrogate with description: http://arks.princeton.edu/ark:/88435/6108vb32x
this description is also available as OCLC record no. 82518882
published by Bonmariage, “Nouvel élément à propos des Qūsūnī”
all images are courtesy of Princeton University Library
for a list of the commentary’s known manuscripts, see Csorba, Late Mamluk Medical Regimen for Travellers, 77-78
On the top of fol. 1a, the book’s title – Kitāb taʾsīs al-ṣiḥḥa bi-sharḥ al-Lamḥa – is written on gold ground in a rectangular panel. The name of the book’s author – Maḥmūd b Aḥmad al-ʿAyntābī – in the central medallion is framed by a two-part bi-rasm statement.

Muḥammad al-Qūṣūnī I (1430-1511) is named in this bi-rasm statement, though without his ism Muḥammad. His laqab Shams al-Dīn (lit. sun of the faith) is highlighted through punning, as he is praised as “al-raʾīs al-shamsī” (lit. the sunny chief).


bi-rasm al-janāb al-ʿālī al-raʾīs al-shamsī Shams al-Dīn
al-Qūṣūnī raʾīs al-aṭibbāʾ bi‘l-diyār al-miṣriyya adāma Allāh
niʿmata-hū
on the order of his excellency the brilliant chief Shams al-Dīn
al-Qūṣūnī, the chief of the physicians of Egypt – may God make
his blessing everlasting
The online cataloguing entry mentions about the first quire (fols. 1-9) that the incomplete quinion misses its first leaf, but no further details about the quire structure are given. Unfortunately, images of the three edges and the endbands were not included into the digital surrogate so that they cannot be checked for traces of disturbed or replaced leaves or quires. Because the codex was scanned as single pages, and not as double-page openings, the stub of a singleton is just about visible between the inner margins of flyleaf and fol. 1a.

The description of the mise-en-page of fols. 1b-2a highlights the text area’s gold-and-black borders and gold-painted floral spray in the top margin of fol. 1b, yet the description does not comment whether this illumination is connected to to the preceding title page or the following leaves.




PUL Islamic Mss. Garrett 570 H, fols. 2b-3a
The commentary concludes with a colophon (fol. 292b), dated 18 Rabīʿ II 870 [ 8 December 1465 ]. About 150 years later, in the 1610s, a note about the reading of the complete commentary– “qirāʾat jamīʿ hādhā al-sharḥ” – in well-attended meetings and at recurring times – “fī majālisa mutaʿaddidatin wa-awqātin mutajaddidatin” was added on a leaf facing the colophon (fols. 293a-293b).


The colophon was written by Abū al-Wafāʾ Muḥammad b. Ismāʿīl. Next to it, in the lower portion of the right margin, Madyan left the impression of a circular seal (diameter = 1.2 cm), inscribed only with his ism Madyan. An undated collation note in a different hand, partially cut off, was written unto the bottom margin.


In the reading statement Madyan first identified the author and the two men through whom the commentary had been transmitted, and then he certified as “Abū al-Ṣalāḥ Madyan b. ʿAbd al-Raḥmān al-ṭabīb bi-Dār al-Shifāʾ bi-Miṣr” (Abū al-Ṣalāḥ Madyan b. ʿAbd al-Raḥmān, physician in the Dār al-Shifāʾ hospital in Cairo) that the reading had began on 1 Rabīʿ I 1020 [ 13 June 1611 ] and was completed on 26 Dhū’l-Ḥijja 1026 [ 4 January 1617 ]. In contrast to reading certificates from the Mamluk era, those who attended these study session with Madyan were not individually listed (for a French summary with a transcription that skipped the shahāda and the ṣālwa at the beginning, see Bonmariage, “Nouvel élément à propos des Qūsūnī:” 271-272).


Writing her 2009 article while working as a cataloguer, Bonmariage took the volume in its current state at face value, since it has no obvious lacunae, replacement leaves, or later additions. She connected the colophon with the bi-rasm statement and concluded that in 1465, when Muḥammad al-Qūṣūnī I commissioned this copy for himself, he was in his 30s and served as a high-ranking physician in Mamluk Egypt. As many owners never write anything into their books, the absence of any other traces possibly left by Muḥammad al-Qūṣūnī I only attracts attention, because Madyan documented in writing and through a seal impression how he used this book – which in its current state does not carry his ownership note – for several years. The exceptional fact that two physicians of the al-Qūṣūnī family, about 150 years apart, seem to be associated with this volume motivated Bonmariage to write about her discovery. At the same time, she was careful not to speculate about this fact.
The comparison of PUL Isl. Mss. Garrett 570 H with the six manuscripts that carry a Muḥammad al-Qūṣūnī ownership note yields the surprising insight that too much information is even more confounding than zero information. The identification of the two physicians is absolutely sound, when evaluated on their own. And yet the volume’s dual connection with the al-Qūṣūnī family seems too good to be true. For me, it is a red flag. Although I am only familiar with the digital surrogate, I suspect, applying Occam’s razor one more time, that fol. 1a with the bi-rasm statement concerning Muḥammad al-Qūṣūnī I is a later addition to a 1465 codex which had been used by Madyan in the 1610s for his reading sessions. Since this manuscript is a formal working copy of a popular commentary, replacing just the first two leaves – as noted earlier, in its current state the first quinion lacks its first leaf – would have been feasible (for the common practice of exchanging title pages, see Carter and Barker, ABC for Book Collectors, 207). Without the illuminated title page, the manuscript can be understood as a formal working copy of a medical textbook, written when its author Ibn al-Amshāṭī (1409-1496) was in his 50s. Approaching this as a historical textbook which despite its popularity stood outside the medical teaching curriculum of the 1610s might explain why Madyan and his colleagues needed more than five years for working through the entire commentary. At the same time, none of these considerations addresses the question whether Madyan ever owned this manuscript.
Acknowledgements
I would like to thank Feras Krimsti and Kaveh Niazi for their help with the reading of the ownership notes.
Bibliography
“Amīn b. Ḥasan al- al-Ḥalawānī al-Madanī.” In Encyclopaedia of Islam, 1t ed., 1: 327.
ʿĀmir, Hanāʾ Fawzī. al-Aṭṭibāʾ al-Qūṣūniyyūn: Dirāsa wa-taḥqīq. Abu Dhabi: al-Majmaʿ al-Thaqāfī, 2002.
Behrens-Abouseif, Doris. Practising Diplomacy in the Mamluk Sultanate: Gifts and Material Culture in the Medieval Islamic world. London: I.B. Tauris, 2014.
Behrens-Abouseif, Doris. The Book in Mamluk Egypt and Syria (1250-1517): Scribes, Libraries and Market. Leiden: Brill, 2019.
Bonmariage, Cécile. “Un nouvel élément à propos des Qūsūnī.” Arabica 56.2-3 (2009): 269-273.
Brentjes, Sonja. Teaching and Learning the Sciences in Islamicate Societies (800-1700). Turnhout, Belgium: Brepols, 2018.
Carter, John, and Nicolas Barker. ABC for Book Collectors. 8th ed. with corrections. New Castle, Del.: Oak Knoll Press, 2006.
Contadini, Anna. “Ayyubid Illustrated Manuscripts and their North Jaziran Neighbours.” In Ayyubid Jerusalem: The Holy City in Context, 1187-1250, edited by Robert Hillenbrand and Sylvia Auld, 179-194. London: Altajir Trust, 2009.
Contadini, Anna. Conoscenza e libertà: Arte islamica al Museo Civico Medievale di Bologna. Genoa: SAGEP, 2024. Italian-English exhibition catalogue.
Csorba, Zsuzsanna. A Late Mamluk Medical Regimen for Travellers: Ibn al-Amshāṭī’s al-Isfār ʿan ḥikam al-asfār. Critical edition, translation, and commentary. Leiden: Brill, 2024.
D’hulster, Kristof. Browsing through the Sultan’s Bookshelves: Towards a Reconstruction of the Library of the Mamluk Sultan Qāniṣawh al-Ghawrī (r. 906-922/1501-1516). Bonn: Bonn University Press, 2021. A changed version (lit. “geänderte Ausgabe”) is available at: https://hdl.handle.net/20.500.11811/11485 New manuscript discoveries have been posted on D’hulster’s acdemia.edu website since 2024: https://uni-m.academia.edu/KristofDhulster/Browsing%20through%20the%20Sultan’s%20Bookshelves:%20Addenda
D’hulster, Kristof. “A Preliminary Handlist of Manuscripts from the Library of al-Ashraf Qāytbāy.” Journal of Islamic Manuscripts 15 (2024): 353-376.
Gottschalk, Hans Ludwig. Islamic Arabic Manuscripts. Edited by Derek Hopwood. Catalogue of the Mingana Collection of Manuscripts, now in the Possession of the Trustees of the Woodbrooke Settlement, Selly Oak, Birmingham 4. Zug, Switzerland: Inter Documentation, 1985.
Grabar, Oleg. “What Does ‘Arab Painting’ Mean?” In Arab Painting: Text and Image in Illustrated Arabic Manuscripts, edited by Anna Contadini, 17-22. Handbuch der Orientalistik. Leiden: Brill, 2007.
Heyd, Uriel. “Moses Hamon, Chief Jewish Physician to Sultan Süleymān the Magnificent.” Oriens 16 (1963): 152-170.
Keegan, Matthew L. “Commentators, Collators, and Copyists: Interpreting Manuscript Variation in the Exordium of Al-Ḥarīrī’s Maqāmāt.” In Arabic Humanities, Islamic Thought: Essays in Honor of Everett K. Rowson, edited by Joseph E. Lowry and Shawkat M. Toorawa, 296-316. Leiden: Brill, 2017.
Machaeva, Orazgozel. Catalogo dei manoscritti islamici conservati nella Biblioteca universitaria di Bologna. Bologna: Paolo Emilio Persiani, 2017.
MacKay, Pierre A. “Certificates of Transmission on a Manuscript of the Maqāmāt of Ḥarīrī (MS. Cairo, Adab 105).” Transactions of the American Philosophical Society 61.4 (1971): 1-81.
Muhanna, Elias I. “The Sultan’s New Clothes: Ottoman-Mamluk Gift Exchange in the Fifteenth Century.” Muqarnas 27 (2010): 189-207.
Quinn, Meredith Moss. “Books and their Readers in Seventeenth-Century Istanbul.” PhD diss. Harvard University, 2016; http://nrs.harvard.edu/urn-3:HUL.InstRepos:33493319.
al-Qūṣūnī, Madyan b. ʿAbd al-Raḥmān. Qāmūs al-aṭibbāʾ wa-nāmūs al-alibbāʾ. 2 vols. Damascus: Majmaʿ al-lugha al-ʿarabiyya, 1979.
Pertsch, Wilhelm. Die arabischen Handschriften der Herzoglichen Bibliothek zu Gotha. Die orientalischen Handschriften zu Gotha III, 3. Gotha: Perthes, 1881.
Ritter, Hellmut. “Autographs in Turkish Libraries.“ Oriens 6.1 (1953): 63-90.
Schäbler, Birgit. “Seetzen, Ulrich Jasper.“ In Neue Deutsche Biographie 24 (2010): 155–156; https://www.deutsche-biographie.de/pnd119328593.html
Sellheim, Rudolf. Materialien zur arabischen Literaturgeschichte. Verzeichnis der Orientalischen Handschriften in Deutschland 17, A. 2 vols. Wiesbaden: Steiner, 1976-1987.
Shefer-Mossensohn, Miri. Ottoman Medicine: Healing and Medical Institutions, 1500-1700. Albany, NY: SUNY Press, 2010.
Talman, Michael. Elenchus librorum Orientalium manuscriptorum, videlicet Græcorum, Arabicorum, Persicorum, Turcicorum, et deinde Hebraicorum, ac antiquorum Latinorum, tam manuscriptorum, tum impressorum a domino comite Aloysio Ferdinando Marsigli […] collectorum, coëmptorúmque. 6 vols. Vienna: Susanna Cristina Cosmerovius, 1702.
Ullmann, Manfred. Die Medizin im Islam. Handbuch der Orientalistik. Leiden: Brill, 1970.
Ullmann, Manfred. Die Geheim- und Naturwissenschaften im Islam. Handbuch der Orientalistik. Leiden: Brill, 1972.
Veselý, Rudolf. An Arabic Diplomatic Document from Egypt: The Endowment Deed of Maḥmūd Pasha dated 974/1567. Prague: Charles University, 1971. The original three-volume doctoral dissertation, written in Czech, was accepted by the Charles University Prague in 1965, and successfully defended in 1966.
Veselý, Rudolf. “Die Hauptprobleme der Diplomatik arabischer Privaturkunden aus dem spätmittelalterlichen Ägypten.” Archiv Orientální 40 (1972): 312-343.
Veselý, Rudolf. “Neues zur Familie al-Qūṣūnī: Ein Beitrag zur Genealogie einer ägyptischen Ärzte- und Gelehrtenfamilie – Mit ‘Ergänzungen‘ von Rudolf Sellheim.” Oriens 33 (1992): 437-444.
Biographical information about Rudolf Sellheim and Rudolf Veselý
Endress, Gerhard. “Rudolf Sellheim.“ Oriens 42.1-2 (2014): 1-19.
Neumann, Christoph K., and Petr Štěpánek. “In memoriam Zdenka Veselá.“ Wiener Zeitschrift für die Kunde des Morgenlandes 88 (1998): 9-13.
Ženka, Josef. “Rudolf Veselý, 1931-2020.” Mamluk Studies Review 23 (2020): 1-21.
corrected and enlarged 2d version, 23 February 2026