Policy Gradient
Policy Gradient
https://www.jianshu.com/p/af668c5d783d
虽然前段时间稍微了解过Policy Gradient,但后来发现自己对其原理的理解还有诸多模糊之处,于是希望重新梳理一番。
Policy Gradient的基础是强化学习理论,同时我也发现,由于强化学习的术语众多,杂乱的符号容易让我迷失方向,所以对我自己而言,很有必要重新确立一套统一的符号使用习惯。UCL的David Silver可谓是强化学习领域数一数二的专家(AlphaGo首席研究员),他的课程在网上也大受欢迎,因此我接下来用于讨论问题的符号体系就以他的课件为准。
Markov Decision Process (MDP)
在概率论和统计学中,Markov Decision Processes (MDP) 提供了一个数学架构模型,刻画的是“如何在部分随机,部分可由决策者控制的状态下进行决策”的过程。强化学习的体系正是构建在MDP之上的。

有了这样的定义,自然引申出policy和reward的概念:


Value function
Value function也是MDP中一个非常重要的概念,衡量的是从某个状态开始计算的reward期望值,但容易令初学者混淆的是,value function一般有两种定义方式。
一种叫state-value function:

另一种叫action-value function,会显式地将当前采取的动作纳入考量之中:

从定义上看,两者显然可以互相转换: 

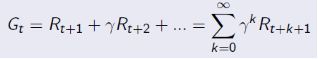
会发现这两种value function其实都可以写成递归的形式:

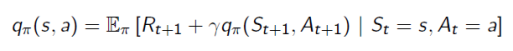
这又被称为Bellman Equation,把value function分解成了immediate reward加上后续状态的discounted value。
Policy Gradient
强化学习的一类求解算法是直接优化policy,而Policy Gradient就是其中的典型代表。
首先需要讨论一下policy的目标函数。一般而言,policy的目标函数主要有三种形式:
- 在episodic环境(有终止状态,从起始到终止的模拟过程称为一个episode,系统通过一次次地模拟episode进行学习)中,衡量从起始状态开始计算的value:
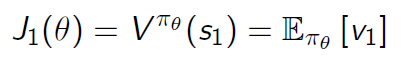
- 在continuing环境(没有终止状态,是一个无限的过程)中,衡量value均值:
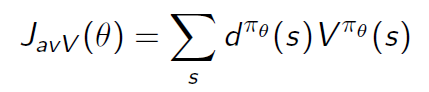
- 不管在哪个环境中,只关注immediate reward,衡量的是每个时刻的平均reward:
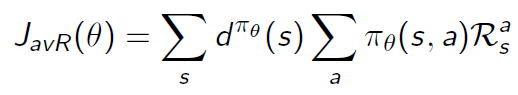
以上的
对目标函数求梯度会用到一个很重要的trick,叫likelihood ratios:
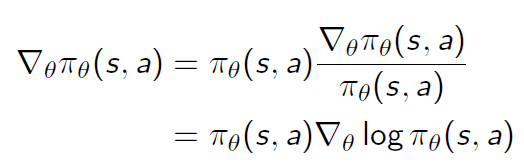
对目标函数求梯度最终都是要转化为对policy求梯度,而这个转化的作用是为了凑出
项,便于后续化简出期望项。 一个简单的例子是考虑最基本的情况——单步的MDP,在执行了一个时间单位之后就终止,所得的reward就等于这个时刻的immediate reward,记为

利用likelihood ratios推导出梯度是:

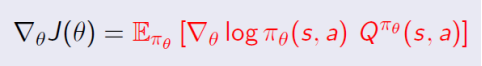
进行无偏采样,记为
,因此可以把期望项去掉,参数更新的公式为:
作者:冯乌尔里希
链接:https://www.jianshu.com/p/af668c5d783d
來源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。
Download: pdf