Policy Gradient Methods for Reinforcement Learning with Function Approximation
Policy Gradient Methods for Reinforcement Learning with Function Approximation
Math Analysis
Markov Decision Processes and Policy Gradient
So far in this book almost all the methods have been action-value methods; they learned the values of actions and then selected actions based on their estimated action values; their policies would not even exist without the action-value estimates. In this chapter we consider methods that instead learn a parameterized policy that can select actions without consulting a value function. A value function may still be used to learn the policy parameter, but is not required for action selection.
| method | Value function | Policy |
| Action-value Methods | Value of actions | would not even exist |
| Policy Gradient Methods | without consulting a value function, or a value function may be used to learn the policy parameter, but is not required for action selection | learn a parameterized policy
|
<Reinforcement Learning, An Introduction> Richard S. Sutton and Andrew G. Barto
这篇论文提出的策略(Policy)用它本身的FA(Function Approximator)来表现,策略与值函数无关,通过期望回报与策略参数的梯度来更新策略。这篇论文主要的新成果是通过一个近似动作值或者高级函数,该梯度能写成适合估计的形式。
Notation
: state transition probabilities.
: expected rewards.
: A policy which the agent’s decision making procedure at each time.
.
: approximate action-value function, function approximation, long-term expected reward per step. two ways of formulating the agent’s objective: average reward formulation and start state formulation.
is independent of state.
: stationary distribution of states under π.
: [0, 1] a discount rate. In start-state formulation, we define
as a discounted weighting of states encountered starting at s0 and then following π :
.
Qπ : the value of a state-action pair given a policy
: 某策略的近似者函数。
: S x A → R be our approximation to Qπ, with parameter ω. 某值函数的近似函数。
: some unbiased estimator of Qπ(st, at ), perhaps Rt.
Proof Key Steps about Theorem 1 (Policy Gradient)
Define
(1)
For the start-state formulation:
(2)
so
(3)
Then, we consider (1) partial differential with respect to theta,
(4)
so
(5)
so
(6)
so
(7)
. . .
Substitute (7) into (6) get 76, then, substitute 76 into (5), then, substitute 765 into (4),
so
assume in start-state formulation:
so
(Q.E.D)
—————————-
Stationary Distribution
殊途同归
or
where
P : 转移概率矩阵
π : 平稳概率分布
例:设状态空间为S={0, 1, 2,}的马尔可夫链,其一步转移概率矩阵为
试分析它的极限分布,平稳分布是否存在?并计算
解:易知此链为不可约遍历链。
故极限分布存在,平稳分布存在唯一,且平稳分布就是其极限分布。
用结果验证,
——————
也就是说,可以将求平稳分布与求特征向量相“联系”起来。
(A : n阶方阵,对应状态空间S的一步转移概率矩阵的转置,
λ: A的特征值,在这里为1,
x: 非零向量,对应转移概率矩阵的转置的特征值为1的特征向量,即平稳分布)
结论:求某状态空间S的马尔可夫链的平稳分布也就是
求其一步转移概率矩阵PT的特征值为1的特征向量。
————————
在状态空间S中,考虑到所有的动作a,进入到下一个状态S’,在本论文中平稳分布是dπ,根据以上有关状态空间S的平稳分布的说明,,则可以得出以下关系式:
For the average-reward formulation:
—————————
Stationary distribution dπ, so sum of probability equals 1:
so
(Q.E.D)
Methods that learn approximations to both policy and value functions are often called actor–critic methods, where ‘actor’ is a reference to the learned policy, and ‘critic’ refers to the learned value function, usually a state-value function.
1. Policy Gradient Theorem
Theorem 1 (Policy Gradient)
For any MDP, in either the average-reward or start-state formulations,
| average-reward formulation | start-state formulation | |
Define
|
||
| Policy Gradient |
In any event, the key aspect of both expressions for the gradient is that their are no terms of the form }{\partial&space;\theta}}) :
the effect of policy changes on the distribution of states does not appear.
换句话说就是,策略变化对于状态分布没有影响。
:
the effect of policy changes on the distribution of states does not appear.
换句话说就是,策略变化对于状态分布没有影响。
2. Policy Gradient with Approximation
Theorem 2 (Policy Gradient with Function Approximation)
If satisfies
(2a)
———————-
这里简单提下公式(2a)的来源,其实就是学习的近似值(对应值函数的真实值Qπ),通过策略π,通过下式的规则
来更新ω,(近似值与真实值Qπ的差的平方求ω偏导成正比),上式红色部分,当过程收敛到一个局部最佳,得到(2a)。
———————-
and is compatible with the policy parameterization in the sense that
(2b)
这个兼容条件compatibility condition很重要,起到‘桥梁’作用,可能是由发现者从结论“反推”得到的
then
(2c)
Proof:
Combining (2a) and (2b),
so
(2d)
so
we use the theorem 1 – equation (2d)
get
(Q.E.D)
3. Application to Deriving Algorithm and Advantages
Consider a policy that is a Gibbs distribution in a linear combination of features:
so
so
也就是说,除了每个状态normalized为均值0(为什么?)之外,还与策略同样的特征必须是线性关系。
In other words, fw must be linear in the same features as the policy, except normalized to be mean zero (why?) for each state.
4. Convergence of Policy Iteration with Function Approximation
Theorem 3 (Policy Iteration with Function Approximation)
,
分别是任何的某策略和某价值函数的可微的近似者函数。同时它们满足公式(2b)即兼容条件,序列
由下面定义:任何θ0,, and
对应(2a)
对应(2c)
收敛至
意味着存在局部最优
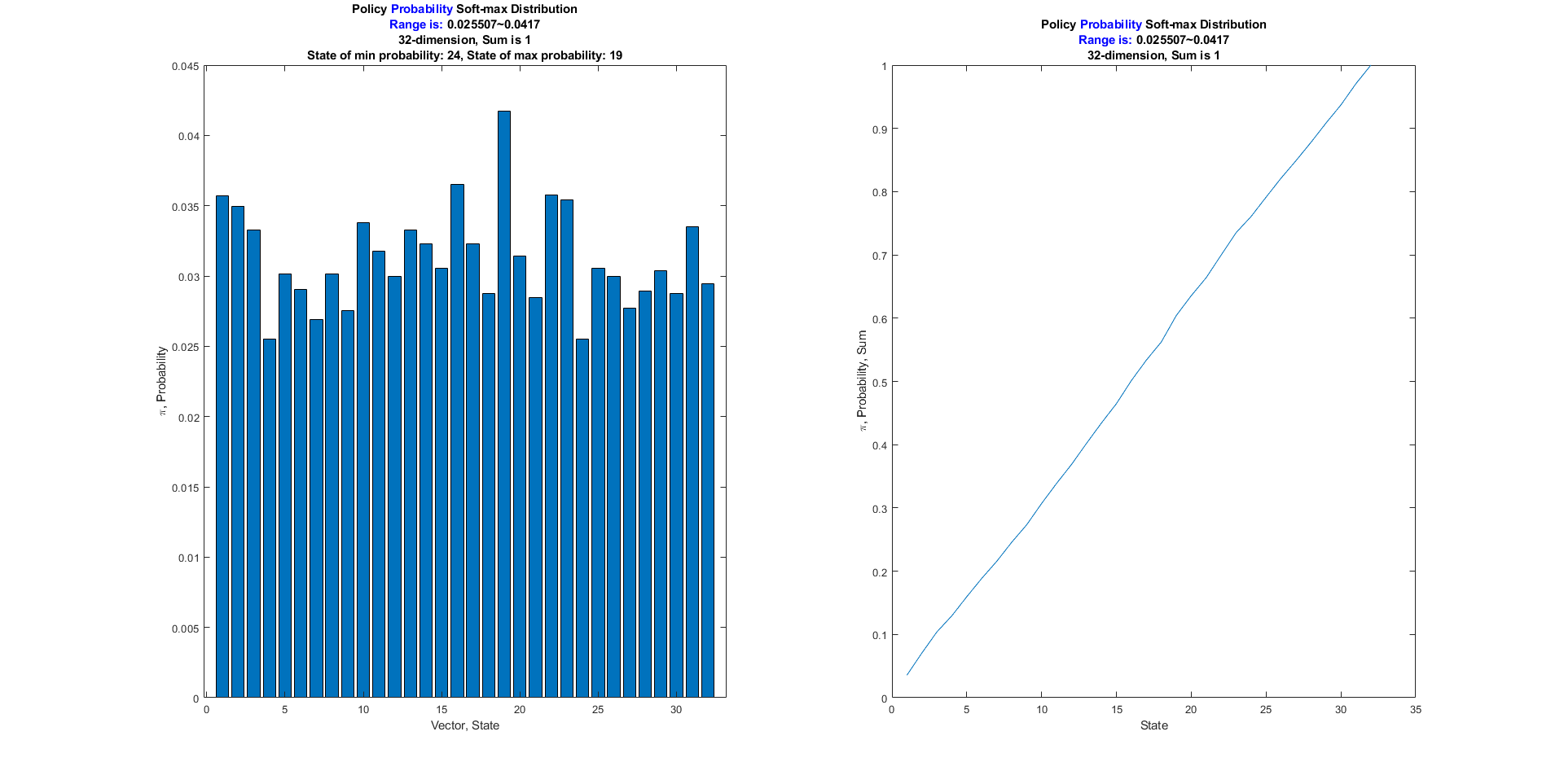
Soft max function, Softargmax, or Normalized Exponential Function
归一化指数函数
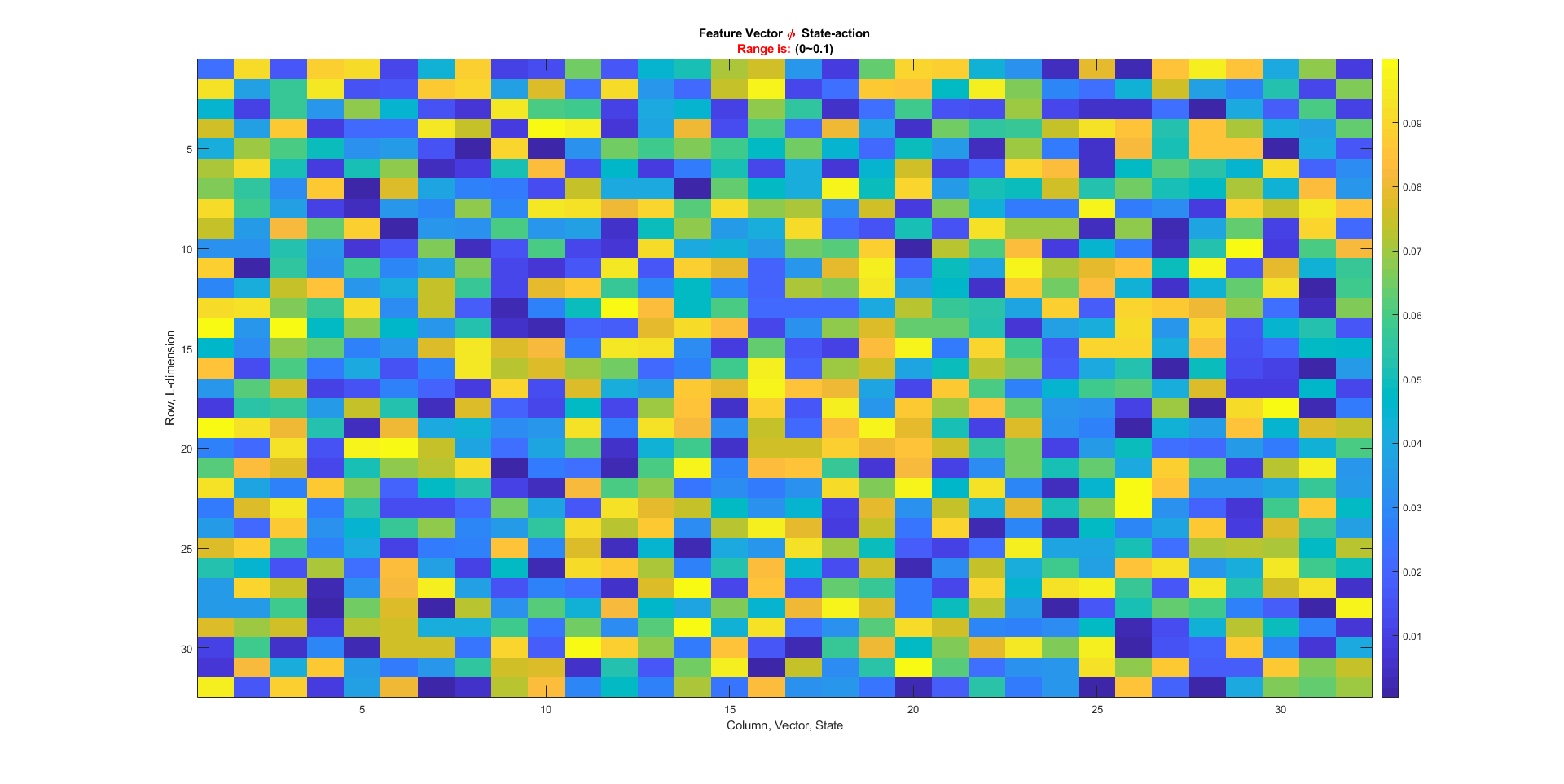
where : an L-dimensional feature vector characterizing state-action pair s, a. 表征状态-动作对的一个L维特征向量。
: the inner product of
and
.
Softmax Distribution Matlab Code@github Private Repository
Exponential Soft-max Distribution
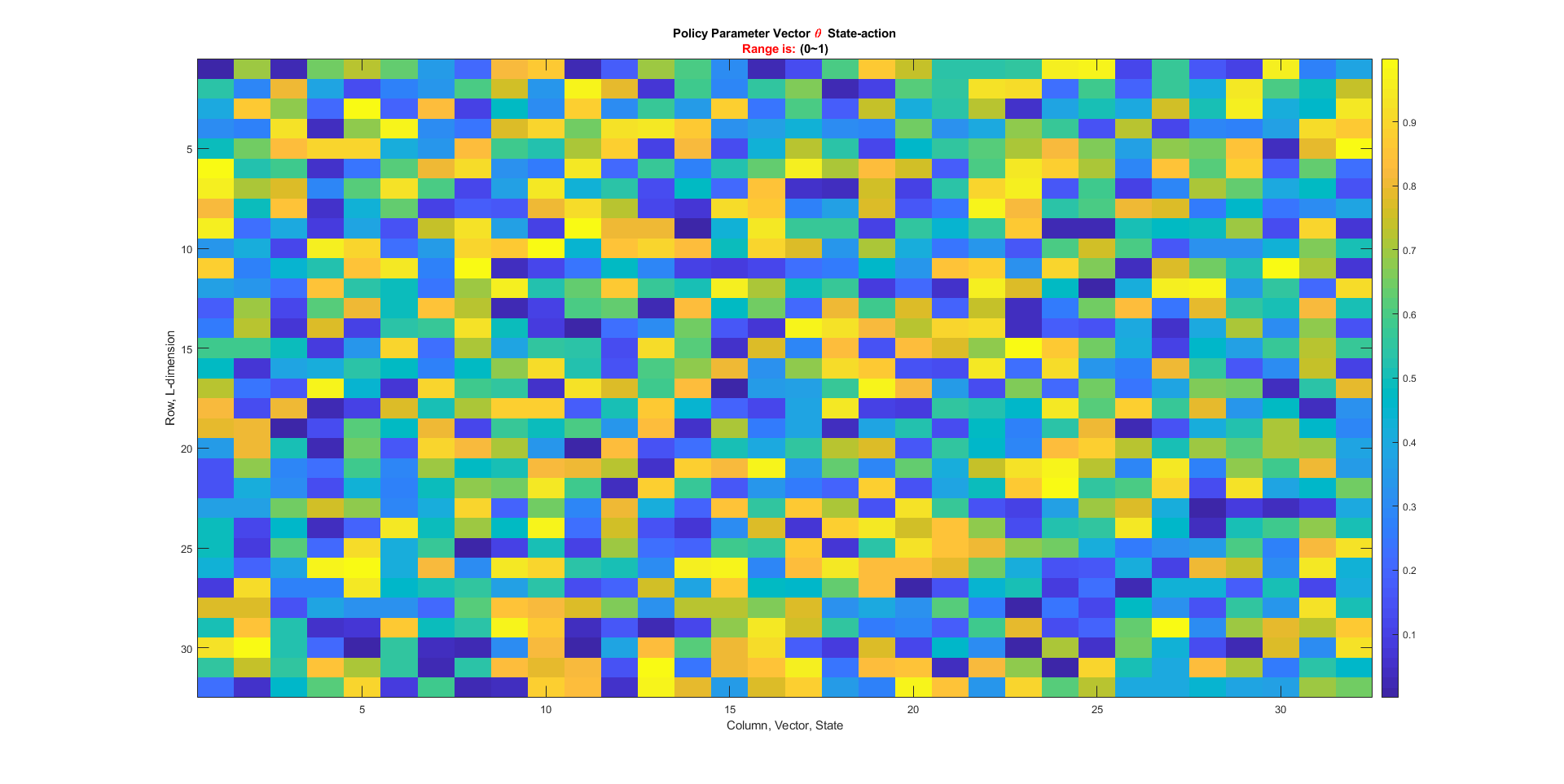
Column is the vector, state.






http://blogs.cuit.columbia.edu/zp2130/policy_gradient/
Download: pdf