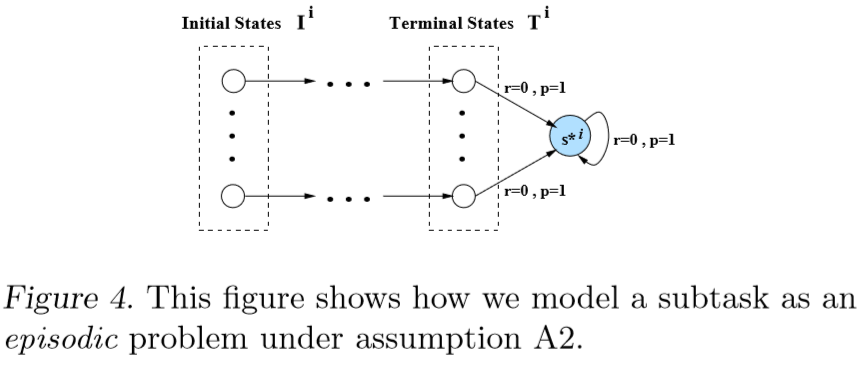
RL Math
February 13, 2025
Neural-network-based decentralized control of continuous-time nonlinear interconnected systems with unknown dynamics Global Value vs. Sub-goals by Policy Gradient Neuro-Dynamic Programming Gradient Methods Framework Policy Gradient Method for Hierarchical RL Policy Gradient HRL Policy Gradient HRL and Neuro-Dynamic Programming Policy Gradient Method for HRL The scanned draft files above contain handwritten mathematical formulas or tools, including… read more »