When Dr. Jaan Altosaar heard that food deprivation increases stem cell regeneration and immune system activity in rats, he did what many would not dare: he decided to try it himself and fasted for five days. Thoughts of food started to take over his mind and, with what can only be qualified as a superhuman ability to think with low blood sugar, he went on a scientific tangent and channeled them into tackling the complicated task of improving food recommendation systems, which led to publishing a research article about it.
Dr. Altosaar wanted help in making decisions because choosing is hard. When faced with an excessive number of options, we fall victim to decision fatigue and tend to prefer familiar things. Companies know this, and many have developed personalized recommendations for many facets of our lives: Facebook’s posts on your timeline, potential partners on dating apps, or suggested products on Amazon. But Jaan had a clear favorite: Spotify’s Discover Weekly algorithm. The music app gathers information on co-occurrence of artists in playlists and compares the representation of you as a listener to the couple billion playlists it has at its disposal to suggest songs you might enjoy. Since Dr. Altosaar’s problem was similar, he framed the problem as feeding the algorithm a user’s favorite recipes (“playlists”), which are made of a list of ingredients (“songs”). Would the algorithm then cook up suggestions of complimentary meals based on the ingredients in them?
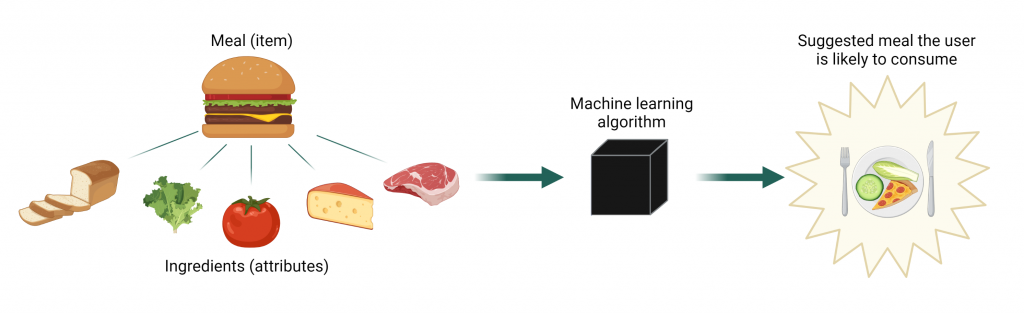
Meal recommendation in an app is challenging on several fronts. First, a food tracking app might record eating the same meal in many different ways or with unique variations (such as a sandwich with homemade hot sauce or omitting pickles). This means that any specific meal is typically only logged by a small number of users. Further, the database of all possible meals a user might track is enormous, and each meal only contains a few ingredients.
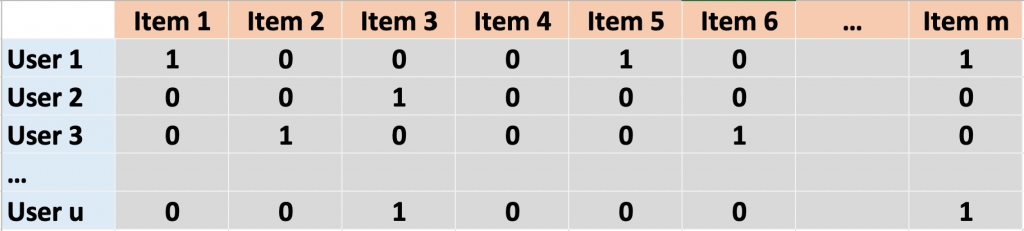
In traditional recommender systems such as those used by Netflix, solving this problem might mean first translating the data into a large matrix where users are rows and items (e.g. movies or meals) are columns. The values in the matrix are ones or zeros depending on whether the user consumed the item or not. Modern versions of recommender systems, including the one in Dr. Altosaar’s paper, also incorporate item attributes (ingredients, availability, popularity) and use them as additional information to better tailor recommendations. An outstanding issue, however, is striking a balance between flexibility, to account for the fact that we are not all like Joey Tribbiani and might not like custard, jam and beef all together (even if we like them separately), and scalability, since an increasing number of attributes takes a toll on computing time. Additionally, these machine learning algorithms are not always trained the same way they are later evaluated for performance.
The new type of model Dr. Altosaar and colleagues propose, RankFromSets, frames the problem as a binary classification. This means that it learns to assign a zero to meals unlikely to be consumed by a user, and a one to those that are likely to be consumed. When faced with giving a user a set of potential meals (say five), it strives to maximize the number of meals the user will actually eat from those five recommended to them. To leverage the power of incorporating the meal’s ingredients, the algorithm uses a technique from natural language processing to learn embeddings. These are a way to compress data to preserve the relevant information you care about to solve your problem; in this case, learning about patterns useful for predicting which ingredients tip the balance for someone to consume a meal. This allows for a numerical representation for each meal based on its constituent foods, and the patterns in how those foods are consumed across all users.
The RankFromSets classification model incorporates several components. There are embeddings for representing user preferences alongside the embeddings corresponding to a meal a user might consume. The classifier is spiced up with additional user-independent information about the meal’s popularity and its availability. These components are used by the model to learn the probability that a particular meal will be consumed by a user. Potential meals a user might enjoy – or that might be healthier options – are then ranked, and the top meals will be recommended to the user. For example, if you have had avocados in every one of your meals, they are in season, and all those Millennials are logging in their avocado toast, you are very likely to receive recommendations that include avocados in the future.
As a proof of concept, the authors tested their method not only on food data, which they got from the LoseIt! weight loss app, but also on a dataset unrelated to meal choices. For this independent data set, the authors used reading choices and behavior among users of arXiv, a preprint server. They trained the model on past user behavior data and evaluated performance (accuracy of paper suggestions) on a previously separated portion of that same data (so they knew whether the user had actually read the paper, but this information was hidden from the algorithm for evaluation). This is a typical way to assess the performance of machine learning systems, and their method outperformed previously-developed recommender systems. The better performance and translatability to tasks other than meal recommendation is indicative of the potential of this tool to be applied in other contexts.
This new recommender system could be applied to either recipe recommendation apps, or even to an app that would suggest first-time customers of a restaurant the menu items that they are more likely to like based on their preferences. The system also has the potential to incorporate additional information beyond whether a user consumed (and liked) a particular ingredient or meal. Sometimes the method of cooking determines whether a food is appealing or not (Brussel sprouts I’m looking at you). Additionally, classifying ingredients by flavor might also be helpful in suggesting similar (and even healthier) alternatives. Therefore, adding those tags as extra layers to the user-meal intersection will certainly provide better recommendations and opportunities to cook outside of the box. Dr. Altosaar’s fast might or might not have gotten him a boost in his stem cells, but he certainly succeeded in helping everyone else worry a bit less about what’s for dinner tonight.
Dr. Jaan Altosaar is a Postdoctoral Research Scientist in the Department of Biomedical Informatics and an active participant in CUPS. He publishes an awesome blog about machine learning and its implications.