i
May 30, 2019
Policy
Policy
Reinforcement Learning is Direct Adaptive Optimal Control How should Reinforcement learning be viewed from a control systems perspective? Control problems can be divided into two classes: regulation and tracking problems, in which the objective is to follow a reference trajectory. optimal control problems, which the objective is to extremize a functional of the controlled system’s… read more »
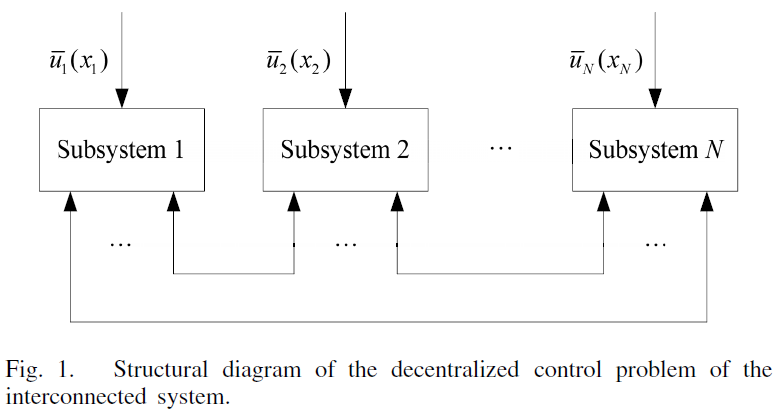
Decentralized Stabilization for a Class of Continuous-Time Nonlinear Interconnected Systems Using Online Learning Optimal Control Approach Neural-network-based Online Learning Optimal Control Decentralized Control Strategy Cost functions (critic neural networks) – local optimal controllers Feedback gains to the optimal control policies – decentralized control strategy Optimal Control Problem (Stabilization) Hamilton-Jacobi-Bellman (HJB) Equations Apply Online Policy Iteration… read more »
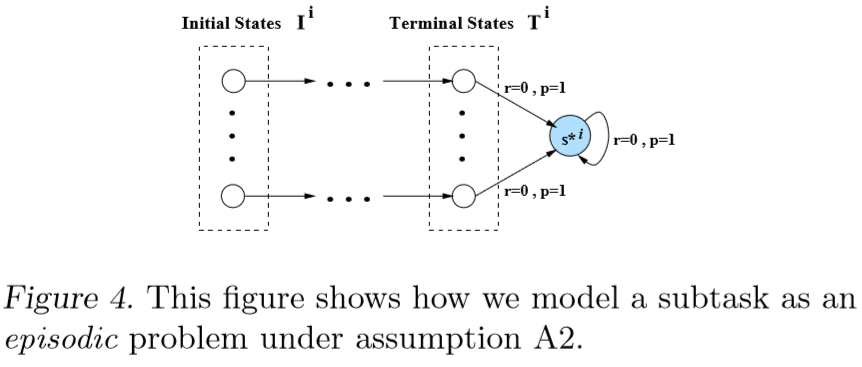
Hierarchical Policy Gradient Algorithms Math Notation M : the overall task MDP. {M0, M1, M2 , M3 , . . . , Mn } : a finite set of subtask MDPs. Mi : subtask, models a subtask in the hierarchy. M0 : root task and solving it solves the entire MDP M. i : non-primitive subtask, paper uses… read more »
Ark and Park
Hierarchical Actor-Critic Download Hierarchical_Actor-Critic Flowchart Terminology Artificial intelligence Optimization/decision/control a Agent Controller or decision maker b Action Control c Environment System d Reward of a stage (Opposite of) Cost of a stage e Stage value (Opposite of) Cost of a state f Value (or state-value) function (Opposite of) Cost function g Maximizing the value function… read more »
There is no excerpt because this is a protected post.
There is no excerpt because this is a protected post.
There is no excerpt because this is a protected post.
There is no excerpt because this is a protected post.